Ankitsrihbti's Categories
Ankitsrihbti's Authors








Latest Saves

(New) paper: https://t.co/9MaYUFluu7
Website: https://t.co/vA5KxsZf6c
🧵
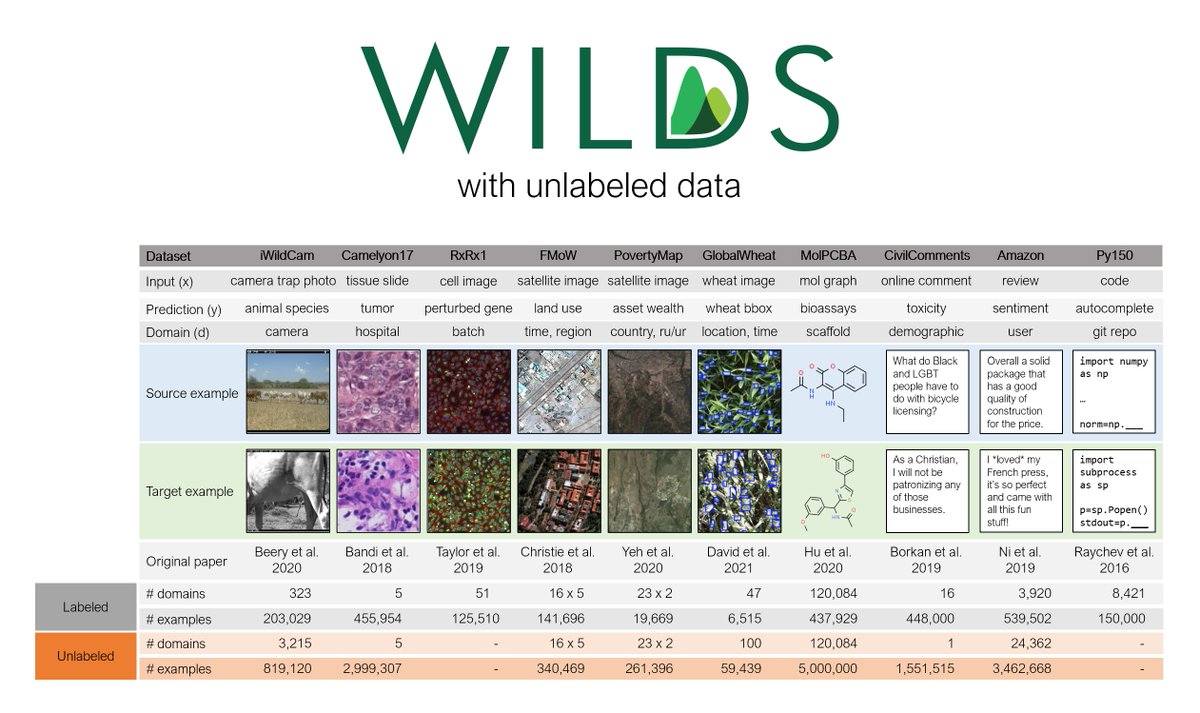
Unlabeled data can be a powerful source of leverage. It comes from a mixture of:
- source domains (same as the labeled training data)
- target domains (same as the labeled test data)
- extra domains with no labeled data.
We illustrate this for the GlobalWheat dataset:

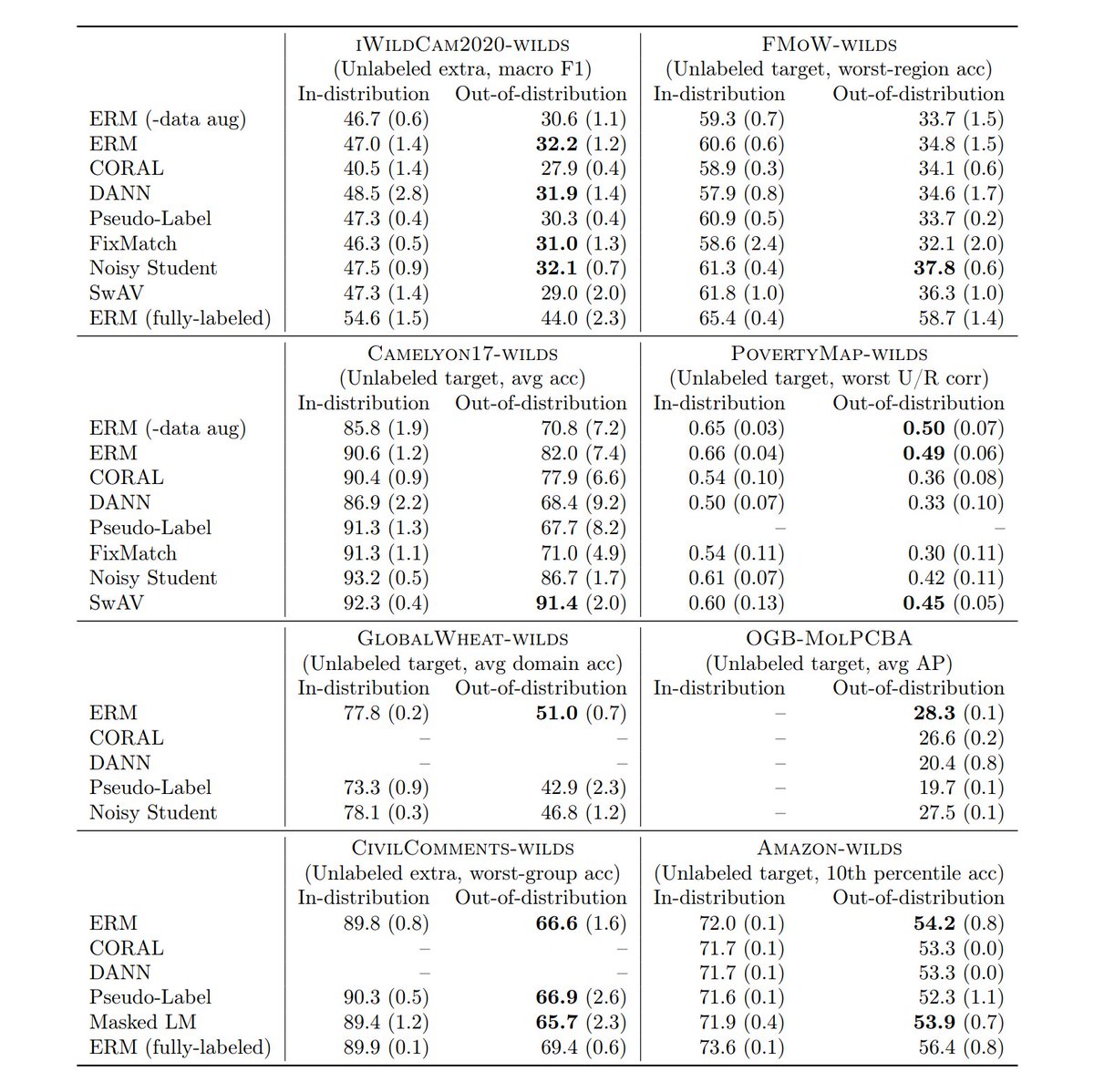
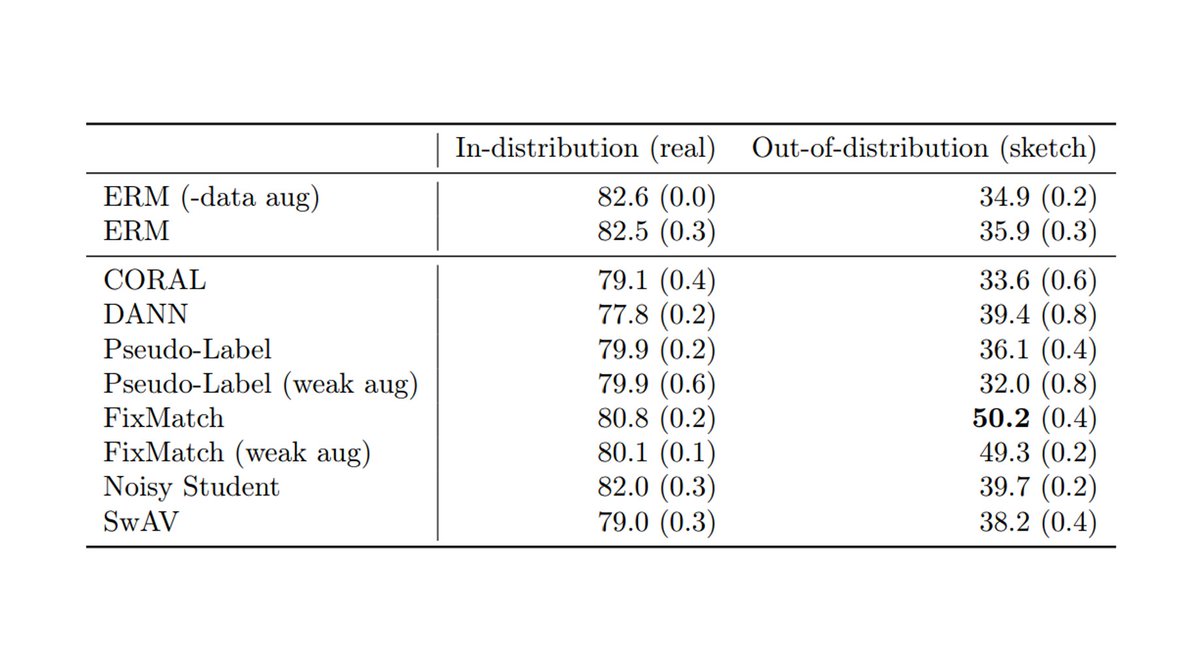
We evaluated domain adaptation, self-training, & self-supervised methods on these datasets. Unfortunately, many methods did not do better than standard supervised training, despite using additional unlabeled data.
This table shows OOD test performance; higher numbers are better.
In contrast, prior work has shown these methods to be successful on standard domain adaptation tasks such as DomainNet, which we replicate below. This underscores the importance of developing and evaluating methods on a broad variety of distribution shifts.
We've added the unlabeled data loaders + method implementations to our Python package: https://t.co/S73kjDxMis. They're easy to use: check out the code snippet below!
We've also updated our leaderboards to accept submissions with and without unlabeled data.


I gathered 12 visual summaries on OD Modeling 🎁
A lot of people find those posts helpful, follow @ai_fast_track to catch the upcoming posts, and give this tweet a quick retweet 🙏
Summary of summaries👇

1- Common Object Detector Architecture you should be familiar
\u2728Common Object Detector Architecture you should be familiar with:
— AI Fast Track (37/45) (@ai_fast_track) October 27, 2021
\U0001f4cc Common object detectors are divided into One-Stage Detectors (OSD), and Two-Stage Detectors (TSD)
\U0001f4cc Both OSD and TSD can be either anchor-based (relying on anchor boxes) or anchor-free pic.twitter.com/TGxS0IbE8g
2- Four Feature Pyramid Network (FPN) Designs you should
4 Feature Pyramid Network (FPN) Design you should know:
— AI Fast Track (37/45) (@ai_fast_track) November 15, 2021
FPN, PANet, NAS-FPN, and BiFPN
\U0001f4cc (a) FPN uses a top-down pathway to fuse multi-scale features from level 3 to 7 (P3 - P7);
\U0001f4cc (b) PANet adds an additional bottom-up pathway on top of FPN; pic.twitter.com/k22vo6Df4L
3- Seven things you should know about the Focal
\U0001f9d07 things you should know about the Focal Loss:
— AI Fast Track (37/45) (@ai_fast_track) October 25, 2021
\U0001f4cc It was introduced in the RetinaNet paper to address the foreground-background class imbalance encountered during training of dense detectors (one-stage detectors)
... pic.twitter.com/NaXzh80Etd
4- FCOS is the first anchor-free object detector that beat two-stage
FCOS is an an anchor-free object detector.
— AI Fast Track (37/45) (@ai_fast_track) November 20, 2021
It was one of first competitors of anchor-based single/two stage object detectors.
Understanding FCOS will help understanding other model inspired by FCOS.
Summary ...\U0001f447 pic.twitter.com/aPFJ0h1olz
Imagine we want to detect all pixels belonging to a traffic light from a self-driving car's camera. We train a model with 99.88% performance. Pretty cool, right?
Actually, this model is useless ❌
Let me explain 👇

The problem is the data is severely imbalanced - the ratio between traffic light pixels and background pixels is 800:1.
If we don't take any measures, our model will learn to classify each pixel as background giving us 99.88% accuracy. But it's useless!
What can we do? 👇
Let me tell you about 3 ways of dealing with imbalanced data:
▪️ Choose the right evaluation metric
▪️ Undersampling your dataset
▪️ Oversampling your dataset
▪️ Adapting the loss
Let's dive in 👇
1️⃣ Evaluation metrics
Looking at the overall accuracy is a very bad idea when dealing with imbalanced data. There are other measures that are much better suited:
▪️ Precision
▪️ Recall
▪️ F1 score
I wrote a whole thread on
How to evaluate your ML model? \U0001f4cf
— Vladimir Haltakov (@haltakov) August 31, 2021
Your accuracy is 97%, so this is pretty good, right? Right? No! \u274c
Just looking at the model accuracy is not enough. Let me tell you about some other metrics:
\u25aa\ufe0f Recall
\u25aa\ufe0f Precision
\u25aa\ufe0f F1 score
\u25aa\ufe0f Confusion matrix
Let's start \U0001f447
2️⃣ Undersampling
The idea is to throw away samples of the overrepresented classes.
One way to do this is to randomly throw away samples. However, ideally, we want to make sure we are only throwing away samples that look similar.
Here is a strategy to achieve that 👇


A Day in the Life of a Trader (A day in my Life)
1) I absolutely love my work❤️! In fact, I grew up dreaming to be a trader. So trading, to me, doesn’t feel like working (except when I lose😂).
It’s fascinating because it’s different every day.
#trading #life

2)7:30 AM : Alarm Rings
A typical week day for me begins at 7:30 AM.
I spend the next 30 minutes on my daily chores — get ready for office, grab a quick breakfast & have a hot cuppa coffee.

3) 8:00 AM : Leave for office
On my way to office, I check what happened at the Wallstreet overnight & how are Asian markets performing.
I then look for any macro news that may affect overnight positions
P.S: We are moving to a new bigger office & will share pics of that soon

4) 9 AM - Connect with Trade Room members
I connect with trade room members on zoom & share my plan for the day, stocks to keep in radar & how to play the index & which option strategies to execute
For more details about Online Trade Room you can check
https://t.co/WrQPxhABsE
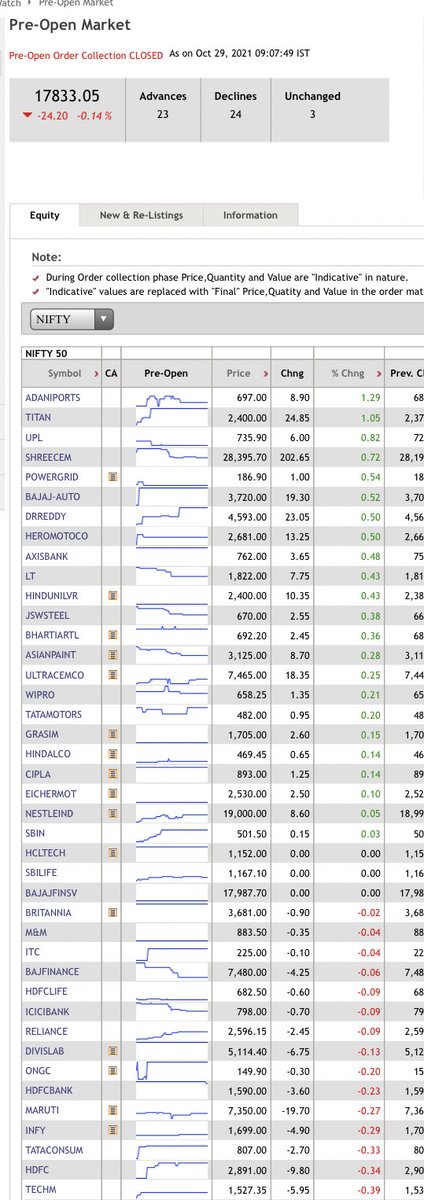
5) 9:07 - Pre Opening session
I keenly observe the pre-opening to get a general sense of where the market is it likely to open. At 9:07 AM, the pre-opening prices are out. I make a note of stocks opening with a big gap up or gap down and keep them on my watchlist.







So in the Dept of Computer Science at Oxford Uni, we run a distinguished lecture series called the Strachey Lectures, after Christopher Strachey, the first director of Oxford's computer
lab: https://t.co/kjYbG2IifM [2/32]
(Strachey was a fascinating character - he got interested in computing after writing to Turing. He died young, and for this reason his story is not so well-known outside Oxford. But this thread is not about him - another time maybe...) [3/32]
Given the boom in AI/ML, it isn't surprising that we've had many leaders in AI/ML give Strachey Lectures, and since they have been recorded, I thought I'd share them... [4/32]
First up: @demishassabis. By coincidence, Demis's lecture was in Feb 2016, just a couple of weeks before the now-famous AlphaGo competition in Seoul with Lee Sedol. [5/32]

We started linking their YouTube videos to https://t.co/BrdfkD9Qof
Let us know if we missed any cool channels.
🧵👇
2/5
Yannic Kilcher @ykilcher
https://t.co/pZoXD2qN3U
⏰~50 min long
His explanations of latest AI papers are awesome. Videos walk through the papers in detail with side notes and highlighting.
3/5 The AI Epiphany @gordic_aleksa
https://t.co/H2dVIkMITx
⏰ ~40 min long
He started discussing latest research about 6 months ago. His videos walk through the papers in detail with notes. He sometimes do coding projects as well.
4/5 Henry AI Labs @labs_henry
https://t.co/LTqwfpFbh8
⏰ ~15 min long
They have a mix of paper explanations, Keras tutorials and weekly updates on new papers published. Paper explanations use slides and cover the important points of the paper.
5/5 Two Minute Papers @twominutepapers
https://t.co/UatgFONZO3
⏰ ~8 min long
They cover of highlights of papers in interesting short videos that are easy to understand. They seem to focus on vision and graphics related research.


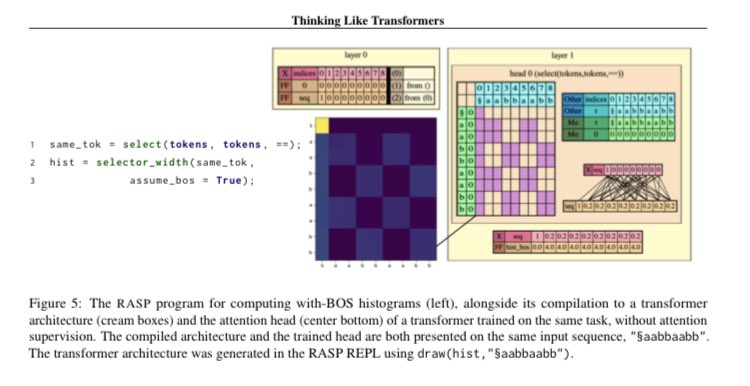
RASP abstracts away low-level operations into simple primitives, allowing a programmer to "think like a transformer" without getting bogged down in the details of how their solution is realised in practice. We use it to imagine how a transformer might solve several formal tasks
Using RASP, we found solutions for problems such as Dyck-k (for any k and depth!), and logical reasoning (in a simplified variant of the task considered in "Transformers as Soft Reasoners over Language"), previously unsolved for the Transformer model
Anyway, this one goes out to my hater, @mmgm
getting rave reviews on my latest venture pic.twitter.com/zXruI4NZvb
— gail weiss (@gail_w) December 7, 2020