Authors Pang Wei Koh
7 days
30 days
All time
Recent
Popular

We're excited to announce WILDS v2.0, which adds unlabeled data to 8 datasets! This lets us benchmark methods for domain adaptation & representation learning. All labeled data & evaluations are unchanged.
(New) paper: https://t.co/9MaYUFluu7
Website: https://t.co/vA5KxsZf6c
🧵
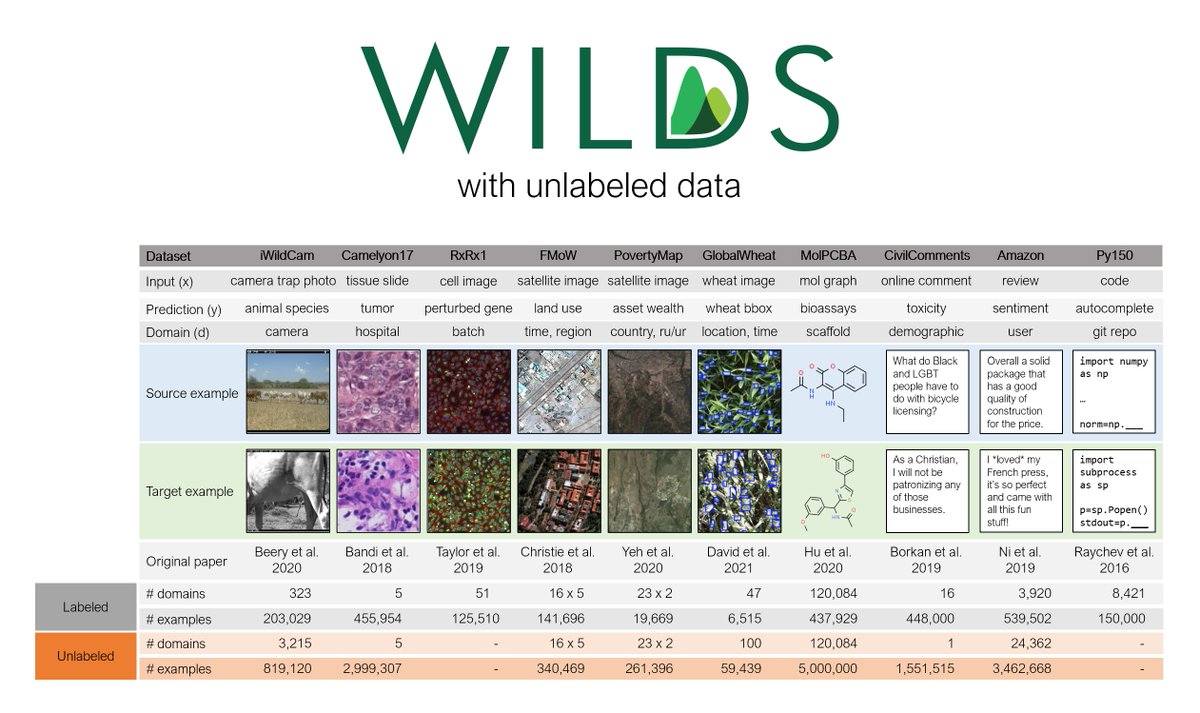
Unlabeled data can be a powerful source of leverage. It comes from a mixture of:
- source domains (same as the labeled training data)
- target domains (same as the labeled test data)
- extra domains with no labeled data.
We illustrate this for the GlobalWheat dataset:

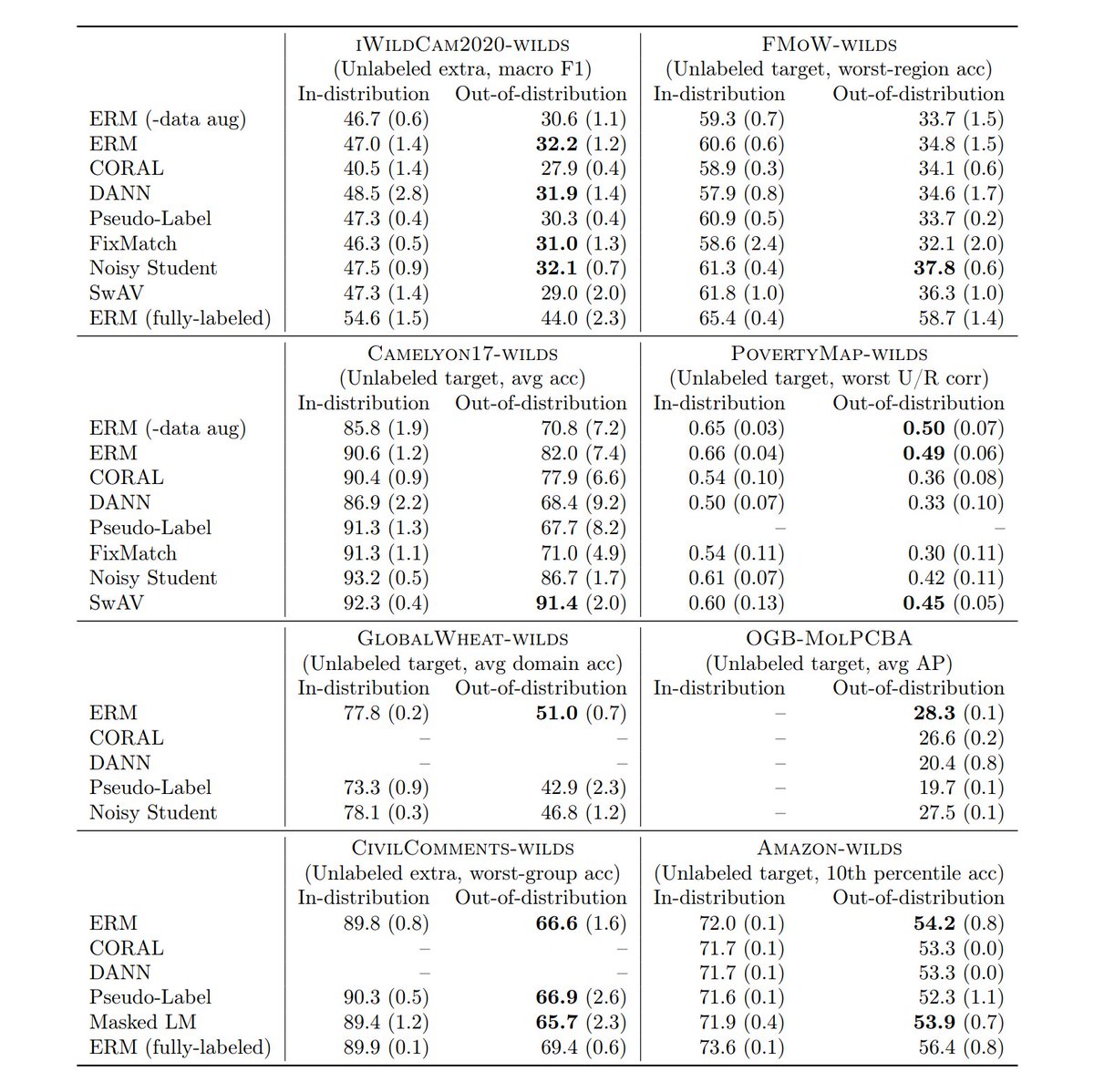
We evaluated domain adaptation, self-training, & self-supervised methods on these datasets. Unfortunately, many methods did not do better than standard supervised training, despite using additional unlabeled data.
This table shows OOD test performance; higher numbers are better.
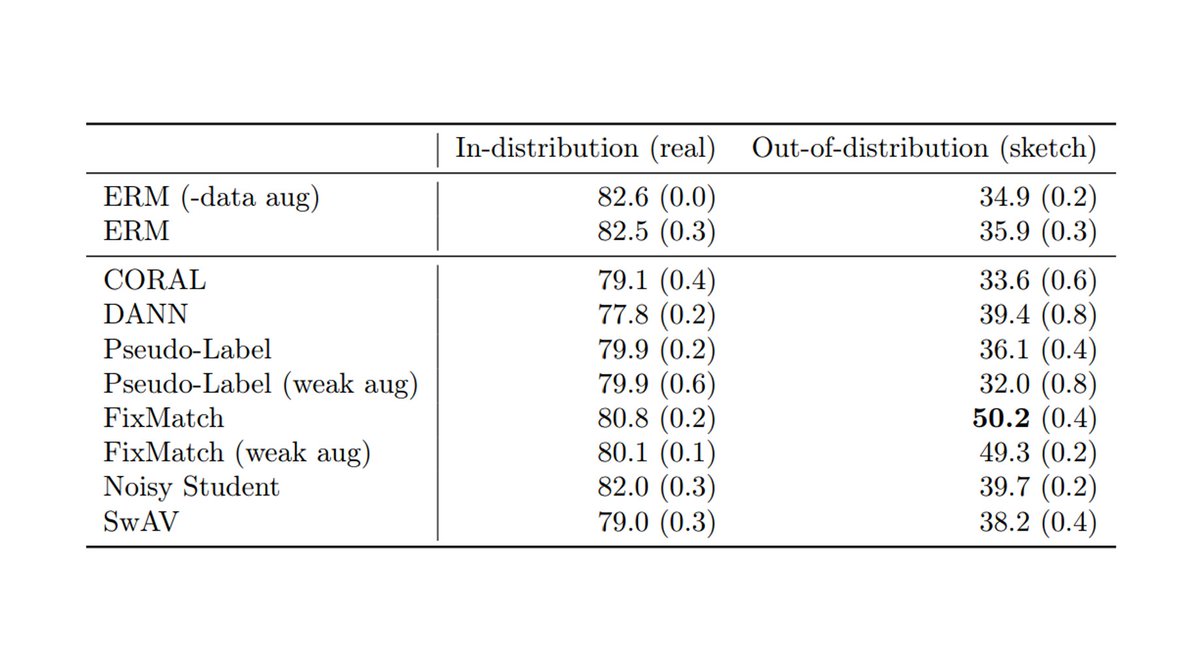
In contrast, prior work has shown these methods to be successful on standard domain adaptation tasks such as DomainNet, which we replicate below. This underscores the importance of developing and evaluating methods on a broad variety of distribution shifts.
We've added the unlabeled data loaders + method implementations to our Python package: https://t.co/S73kjDxMis. They're easy to use: check out the code snippet below!
We've also updated our leaderboards to accept submissions with and without unlabeled data.

(New) paper: https://t.co/9MaYUFluu7
Website: https://t.co/vA5KxsZf6c
🧵
Unlabeled data can be a powerful source of leverage. It comes from a mixture of:
- source domains (same as the labeled training data)
- target domains (same as the labeled test data)
- extra domains with no labeled data.
We illustrate this for the GlobalWheat dataset:
We evaluated domain adaptation, self-training, & self-supervised methods on these datasets. Unfortunately, many methods did not do better than standard supervised training, despite using additional unlabeled data.
This table shows OOD test performance; higher numbers are better.
In contrast, prior work has shown these methods to be successful on standard domain adaptation tasks such as DomainNet, which we replicate below. This underscores the importance of developing and evaluating methods on a broad variety of distribution shifts.
We've added the unlabeled data loaders + method implementations to our Python package: https://t.co/S73kjDxMis. They're easy to use: check out the code snippet below!
We've also updated our leaderboards to accept submissions with and without unlabeled data.