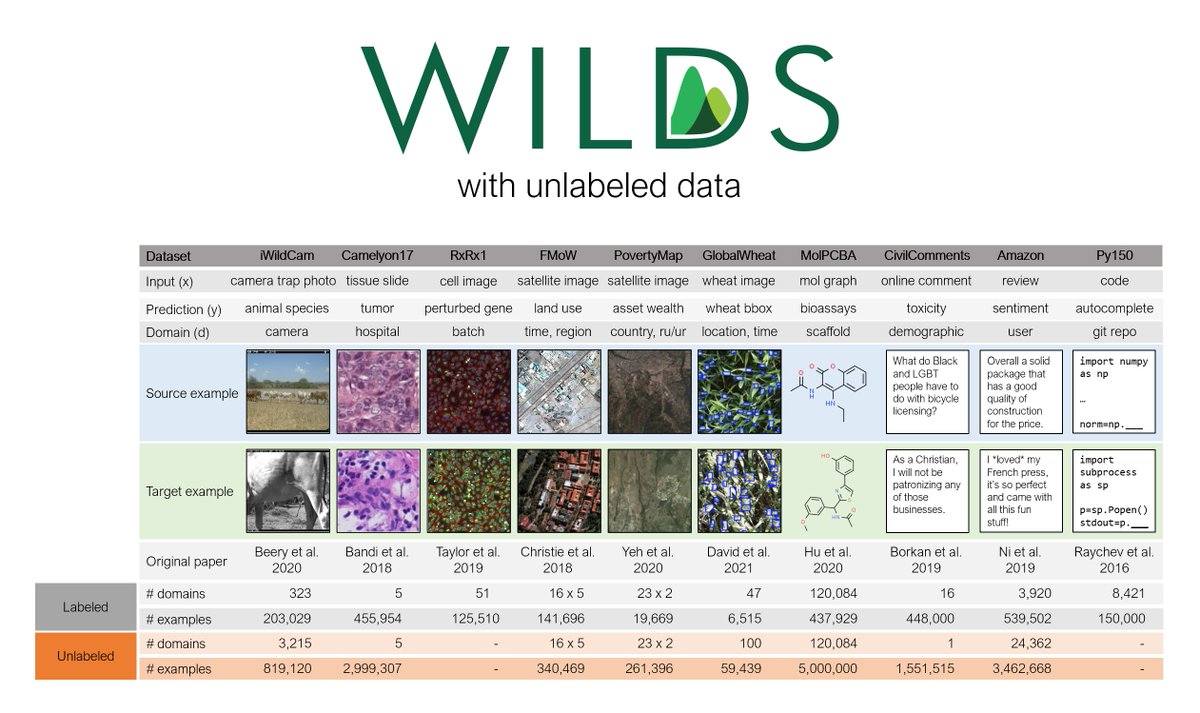
- source domains (same as the labeled training data)
- target domains (same as the labeled test data)
- extra domains with no labeled data.
We illustrate this for the GlobalWheat dataset:




I interviewed 5 billionaires this week
— GREG ISENBERG (@gregisenberg) January 23, 2021
I asked them to share their lessons learned on startups, life and entrepreneurship:
Here's what they told me:
To outperform, you need serious competitive advantages.
— Sahil Bloom (@SahilBloom) March 20, 2021
But contrary to what you have been told, most of them don't require talent.
10 competitive advantages that you can start developing today:
I\u2019ve gotten a lot of bad advice in my career and I see even more of it here on Twitter.
— Nick Huber (@sweatystartup) January 3, 2021
Time for a stiff drink and some truth you probably dont want to hear.
\U0001f447\U0001f447
THREAD: 10 significant lies you're told about the world.
— Julian Shapiro (@Julian) January 9, 2021
On startups, writing, and your career: