Ankitsrihbti's Categories
Ankitsrihbti's Authors








Latest Saves

How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)

Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)
Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)


















Can we get robots to follow language directions without any data that has both nav trajectories and language? In LM-Nav, we use large pretrained language models, language-vision models, and (non-lang) navigation models to enable this in zero shot!
https://t.co/EVsFOj1JhS
Thread:

LM-Nav first uses a pretrained language model (LLM) to extract navigational landmarks from the directions. It uses a large pretrained navigation model (VNM) to build a graph from previously seen landmarks, describing what can be reached from what. Then...
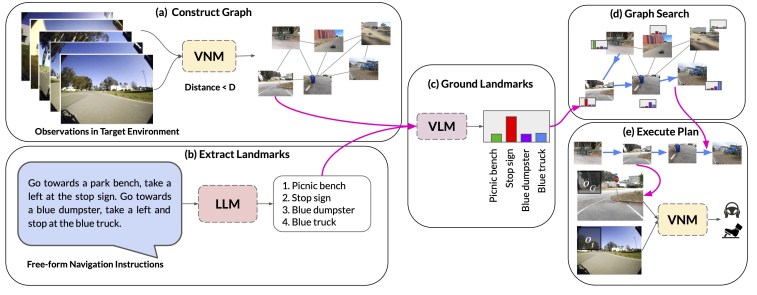
It uses a vision-language model (VLM, CLIP in our case) to figure out which landmarks extracted from the directions by the LLM correspond to which images in the graph, and then queries the VNM to determine the robot controls to navigate to these landmarks.
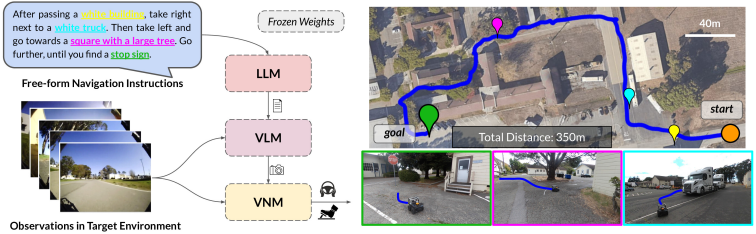
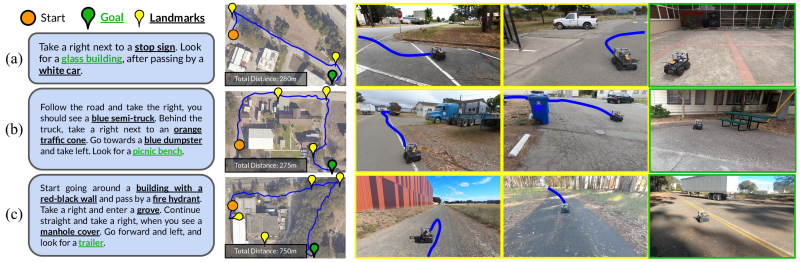
The results in fully end-to-end image-based autonomous navigation directly from user language instructions. All components are large pretrained models, without hand-engineered localization or mapping systems. See example paths below.
LM-Nav uses the ViKiNG Vision-Navigation Model (VNM): https://t.co/oR1bplIvMt
This enables image-based navigation from raw images.
w/ @shahdhruv_, @blazejosinski, @brian_ichter
Paper: https://t.co/ymU9kALQ9G
Web: https://t.co/EVsFOj1JhS
Video:
https://t.co/EVsFOj1JhS
Thread:
LM-Nav first uses a pretrained language model (LLM) to extract navigational landmarks from the directions. It uses a large pretrained navigation model (VNM) to build a graph from previously seen landmarks, describing what can be reached from what. Then...
It uses a vision-language model (VLM, CLIP in our case) to figure out which landmarks extracted from the directions by the LLM correspond to which images in the graph, and then queries the VNM to determine the robot controls to navigate to these landmarks.
The results in fully end-to-end image-based autonomous navigation directly from user language instructions. All components are large pretrained models, without hand-engineered localization or mapping systems. See example paths below.
LM-Nav uses the ViKiNG Vision-Navigation Model (VNM): https://t.co/oR1bplIvMt
This enables image-based navigation from raw images.
w/ @shahdhruv_, @blazejosinski, @brian_ichter
Paper: https://t.co/ymU9kALQ9G
Web: https://t.co/EVsFOj1JhS
Video:

Very excited to present Minerva🦉: a language model capable of solving mathematical questions using step-by-step natural language reasoning.
Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM. https://t.co/bQJOyMSCD4
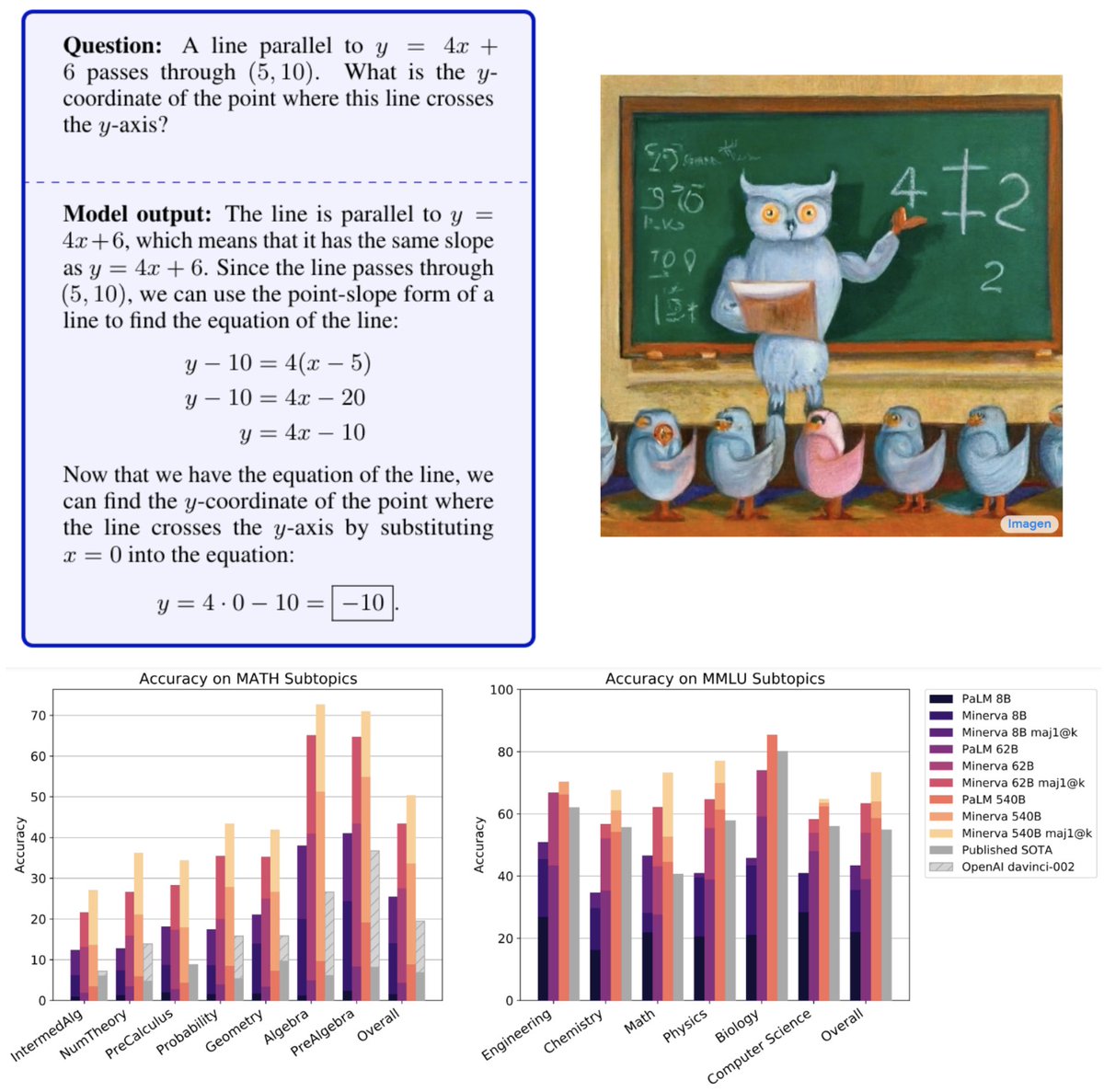
Starting from PaLM🌴, Minerva was trained on a large dataset made of webpages with mathematical content and scientific papers. At inference time, we used chain-of-thought/scratchpad and majority voting to boost performance without the assistance of external tools.

Models' mistakes are easily interpretable. Despite impressive arithmetic skills it still makes calculation mistakes. We estimate the false positive rate due to achieving the right answer from incorrect reasoning and find it relatively low. More samples: https://t.co/YFvsFd6kZ1!

Evaluating our model in 2022 Poland’s National Math Exam it performed above the national average, it solved more than 80% GCSE Higher Mathematics problems and evaluated a variety of STEM undergraduate problems from MIT, it solved nearly a third of them.

Paper: https://t.co/W8t2m02UO8
Great collaboration with Anders, @dmdohan, @ethansdyer, @hmichalewski, @vinayramasesh, @AmbroseSlone, @cem__anil, Imanol, Theo, @Yuhu_ai_, @bneyshabur, @guygr and @vedantmisra !

Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM. https://t.co/bQJOyMSCD4
Starting from PaLM🌴, Minerva was trained on a large dataset made of webpages with mathematical content and scientific papers. At inference time, we used chain-of-thought/scratchpad and majority voting to boost performance without the assistance of external tools.
Models' mistakes are easily interpretable. Despite impressive arithmetic skills it still makes calculation mistakes. We estimate the false positive rate due to achieving the right answer from incorrect reasoning and find it relatively low. More samples: https://t.co/YFvsFd6kZ1!
Evaluating our model in 2022 Poland’s National Math Exam it performed above the national average, it solved more than 80% GCSE Higher Mathematics problems and evaluated a variety of STEM undergraduate problems from MIT, it solved nearly a third of them.
Paper: https://t.co/W8t2m02UO8
Great collaboration with Anders, @dmdohan, @ethansdyer, @hmichalewski, @vinayramasesh, @AmbroseSlone, @cem__anil, Imanol, Theo, @Yuhu_ai_, @bneyshabur, @guygr and @vedantmisra !

Understanding NeRF or Neural Radiance Fields 🧐
It is a method that can synthesize new views of 3D scenes using a small number of input views.
As part of the @weights_biases blogathon (https://t.co/tRddw6jXeA), here are some articles to understand them
1/

Want to dive head first into some code? 🤿
Here is an implementation of NeRF using JAX & Flax https://t.co/pKO5NDSDqv.
The Report used W&B to track the experiments, compare results, ensure reproducibility, and track utilization of the TPU during the experiment.
2/
Mip-NeRF 360 is a follow-up work that looks at whether it's possible to effectively represent an unbounded scene, where the camera may point in any direction and content may exist at any distance.
https://t.co/QNY6VuN8zd
3/

Training a single NeRF does not scale when trying to represent scenes as large as cities.
To overcome this challenge, Block-NeRF was introduced which yields some amazing reconstructions of San Francisco. Here's one of Lombard Street.
4/

They built their implementation on top of Mip-NeRF, and also combine many NeRFs to reconstruct a coherent large environment from millions of images.
🐝Read more here:
It is a method that can synthesize new views of 3D scenes using a small number of input views.
As part of the @weights_biases blogathon (https://t.co/tRddw6jXeA), here are some articles to understand them
1/
Want to dive head first into some code? 🤿
Here is an implementation of NeRF using JAX & Flax https://t.co/pKO5NDSDqv.
The Report used W&B to track the experiments, compare results, ensure reproducibility, and track utilization of the TPU during the experiment.
2/
Mip-NeRF 360 is a follow-up work that looks at whether it's possible to effectively represent an unbounded scene, where the camera may point in any direction and content may exist at any distance.
https://t.co/QNY6VuN8zd
3/
Training a single NeRF does not scale when trying to represent scenes as large as cities.
To overcome this challenge, Block-NeRF was introduced which yields some amazing reconstructions of San Francisco. Here's one of Lombard Street.
4/
They built their implementation on top of Mip-NeRF, and also combine many NeRFs to reconstruct a coherent large environment from millions of images.
🐝Read more here:








