
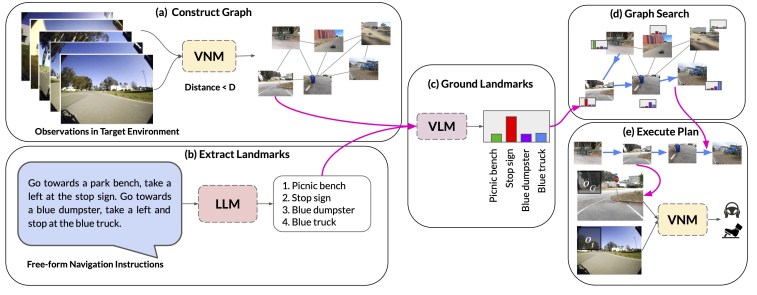
Can we get robots to follow language directions without any data that has both nav trajectories and language? In LM-Nav, we use large pretrained language models, language-vision models, and (non-lang) navigation models to enable this in zero shot!
https://t.co/EVsFOj1JhS
Thread:

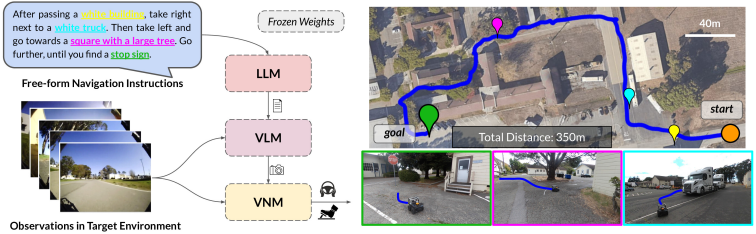
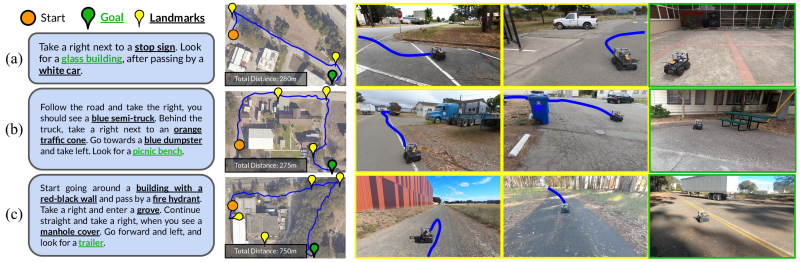
This enables image-based navigation from raw images.
w/ @shahdhruv_, @blazejosinski, @brian_ichter
Paper: https://t.co/ymU9kALQ9G
Web: https://t.co/EVsFOj1JhS
Video: https://t.co/QRhQDAZydM
Of course, our colab won't make a robot materialize and drive around, but you can play with the graph and the LLM+LVM components 😉































