Ankitsrihbti's Categories
Ankitsrihbti's Authors








Latest Saves





As promised in paper, torchdistill now supports 🤗 @huggingface transformers, accelerate & datasets packages for deep learning & knowledge distillation experiments with ⤵️ LOW coding cost😎
https://t.co/4cWQIL8x1Z
Paper, new results, trained models and Google Colab are 🔽
1/n
Paper: https://t.co/GX9JaDRW2r
Preprint: https://t.co/ttiihRjFmG
This work contains the key concepts of torchdistill and reproduced ImageNet results with KD methods presented at CVPR, ICLR, ECCV and NeurIPS
Code, training logs, configs, trained models are all available🙌
2/n
With the latest torchdistill, I attempted to reproduce TEST results of BERT and apply knowledge distillation to BERT-B/L (student/teacher) to improve BERT-B for GLUE benchmark
BERT-L (FT): 80.2 (80.5)
BERT-B (FT): 77.9 (78.3)
BERT-B (KD): 78.9
The pretrained model weights are available @huggingface model hub🤗
https://t.co/mYapfFGoxH
For these experiments, I used Google Colab as computing resource🖥️
So, you should be able to try similar experiments based on the following examples!
https://t.co/4cWQIL8x1Z
Paper, new results, trained models and Google Colab are 🔽
1/n
Paper: https://t.co/GX9JaDRW2r
Preprint: https://t.co/ttiihRjFmG
This work contains the key concepts of torchdistill and reproduced ImageNet results with KD methods presented at CVPR, ICLR, ECCV and NeurIPS
Code, training logs, configs, trained models are all available🙌
2/n
With the latest torchdistill, I attempted to reproduce TEST results of BERT and apply knowledge distillation to BERT-B/L (student/teacher) to improve BERT-B for GLUE benchmark
BERT-L (FT): 80.2 (80.5)
BERT-B (FT): 77.9 (78.3)
BERT-B (KD): 78.9
The pretrained model weights are available @huggingface model hub🤗
https://t.co/mYapfFGoxH
For these experiments, I used Google Colab as computing resource🖥️
So, you should be able to try similar experiments based on the following examples!
Calculating Convolution sizes is something that I found particularly hard after understanding convolutions for the first time.
I couldn't remember the formula because I didn't understand its working exactly.
So here's my attempt to get some intuition behind the calculation.🔣👇
BTW if you haven't read the thread 🧵 on 1D, 2D, 3D CNN, you may want to check it out
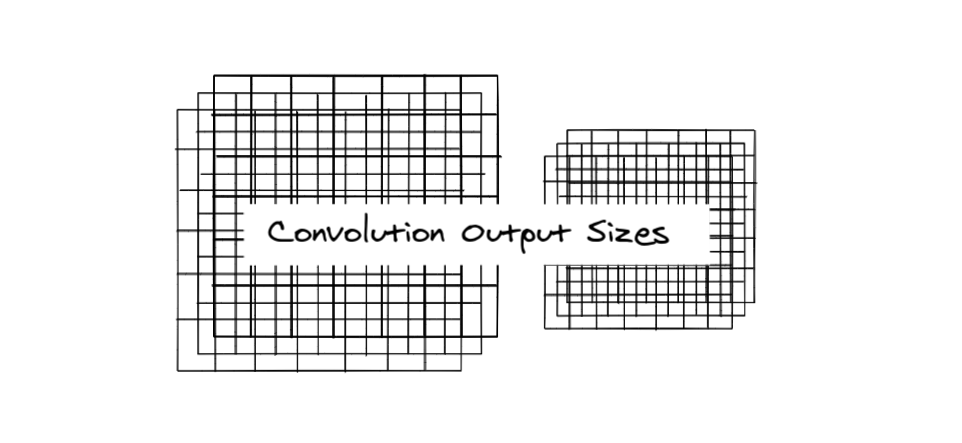
First, observe the picture below🖼
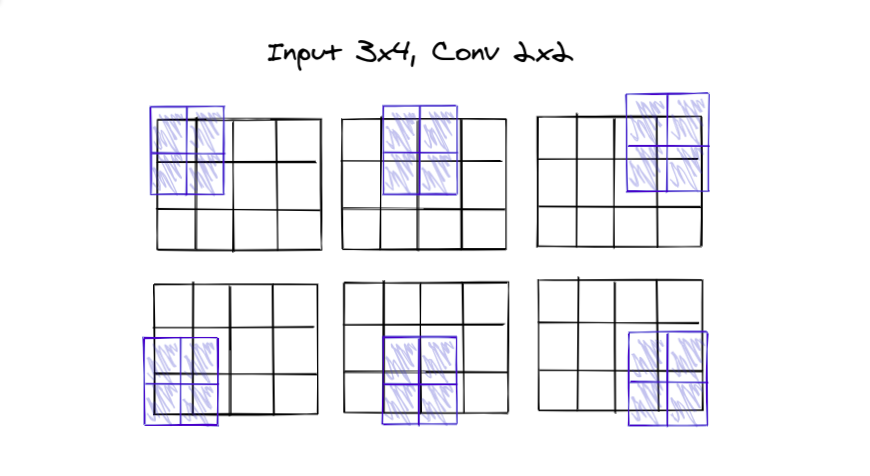
The 2 x 2 filter slides over the
3 rows, 2 times and,
4 columns, 3 times
So, let's try subtracting the filter size first
3 - 2 = 1
4 - 2 = 2
Looks short, we'll need to compensate the 1 in both.
3 - 2 + 1 = 2
4 - 2 + 1 = 3
hence the formula so far becomes:
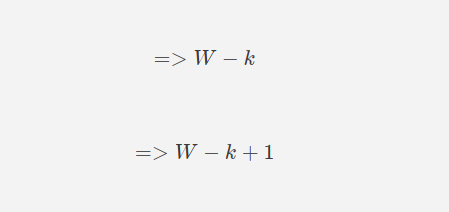
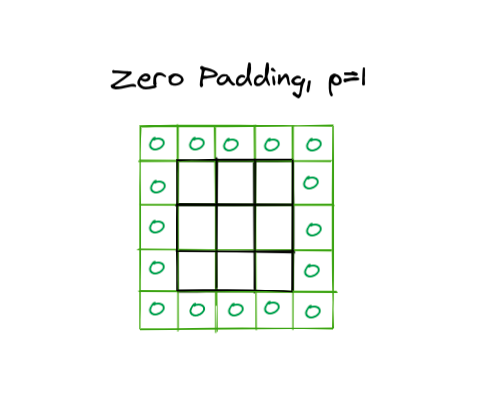
Now let's discuss padding0⃣
Zero padding makes it possible to get output equal to the input by adding extra columns.
It provides extra space for the sliding, making up for the lost space
I couldn't remember the formula because I didn't understand its working exactly.
So here's my attempt to get some intuition behind the calculation.🔣👇
BTW if you haven't read the thread 🧵 on 1D, 2D, 3D CNN, you may want to check it out
Convolutions! 1D! 2D! 3D!\U0001f532
— Prashant (@capeandcode) April 14, 2021
I've had a lot of trouble understanding different convolutions
What do different convolutions do anyway\u2753
Without the correct intuition, I found defining any CNN architecture very unenjoyable.
So, here's my little understanding (with pictures)\U0001f5bc\U0001f447 pic.twitter.com/dCu70j6Ep6
First, observe the picture below🖼
The 2 x 2 filter slides over the
3 rows, 2 times and,
4 columns, 3 times
So, let's try subtracting the filter size first
3 - 2 = 1
4 - 2 = 2
Looks short, we'll need to compensate the 1 in both.
3 - 2 + 1 = 2
4 - 2 + 1 = 3
hence the formula so far becomes:
Now let's discuss padding0⃣
Zero padding makes it possible to get output equal to the input by adding extra columns.
It provides extra space for the sliding, making up for the lost space










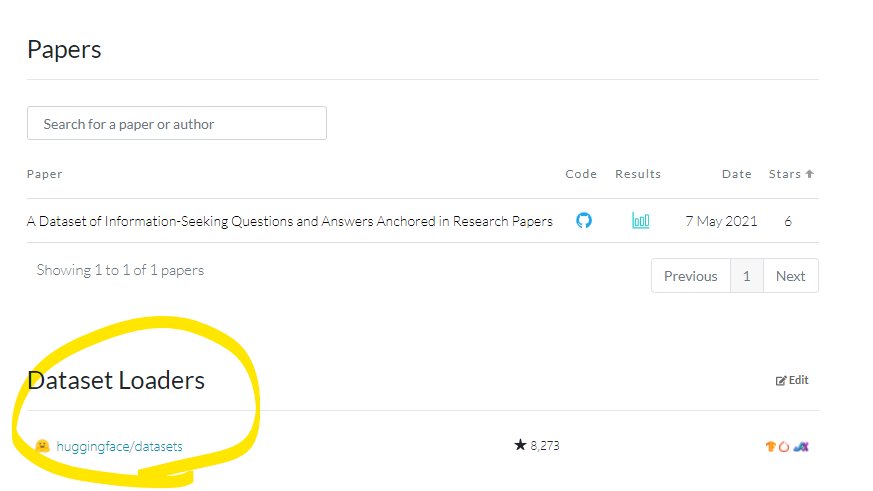

✨ New Feature: Dataset Loaders! ✨
Easily find code to load datasets in your preferred framework!
Supporting: @huggingface datasets, TensorFlow datasets, OpenMMLab, AllenNLP, and many more libraries!
Example: https://t.co/23iztGxyBV
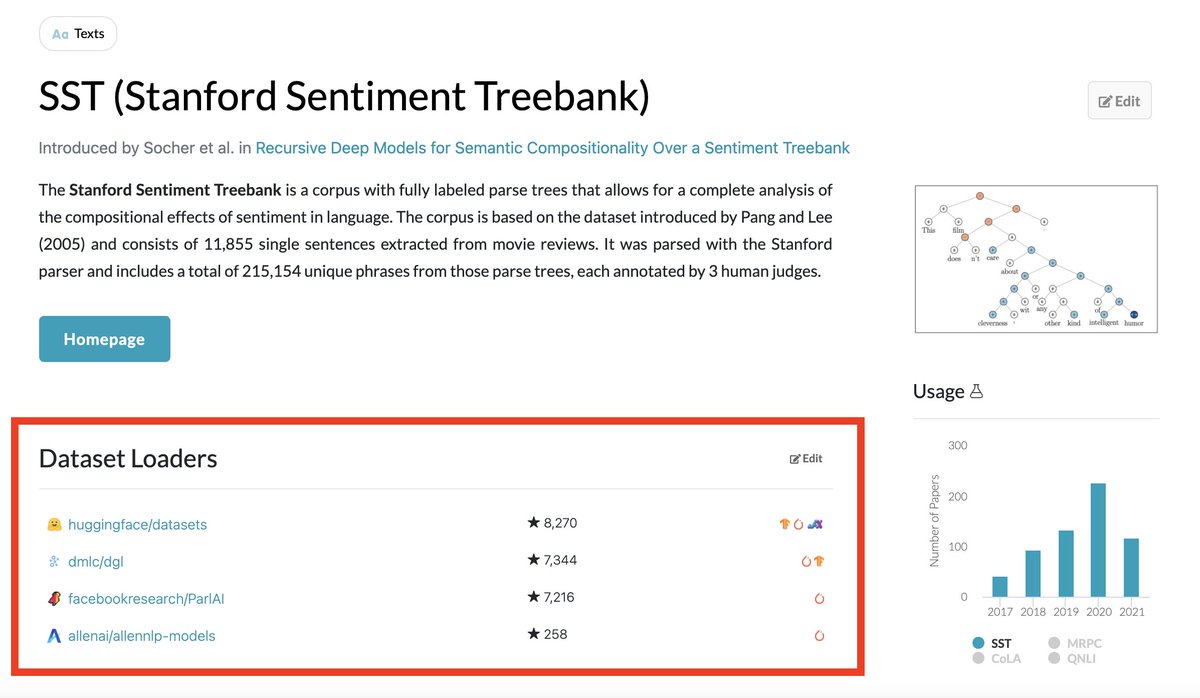
Thanks to the awesome @huggingface team for this collaboration
Easily find code to load datasets in your preferred framework!
Supporting: @huggingface datasets, TensorFlow datasets, OpenMMLab, AllenNLP, and many more libraries!
Example: https://t.co/23iztGxyBV
Thanks to the awesome @huggingface team for this collaboration
Thanks to @paperswithcode, you can now find the leaderboard associated with most of the 900+ datasets on the Hugging Face Hub (https://t.co/d8vPIY4HUm)!
— Hugging Face (@huggingface) May 27, 2021
This is one step towards helping the community find the best models for their applications - we hope you find it useful! pic.twitter.com/wRHPiNkh4N
Text Normalization (TN) are techniques in the field of #NLP that are used to prepare text, sentences, and words for further processing or analysis.
Two of the most common TN techniques are Stemming and Lemmatization. In the next thread🧵 I will briefly tell you about them.
1/5

The aim of both methods (Stemming and Lemmatization) is the same: to reduce the inflectional forms of each word/term into a common base or root.
So what is the difference between them?
2/5
Stemming: process in which terms are transformed to their root in order to reduce the size of the vocabulary. It is carried by applying word reduction rules.
Two of the most common stemming algorithms are:
▪️Porter
▪️Snowball
3/5
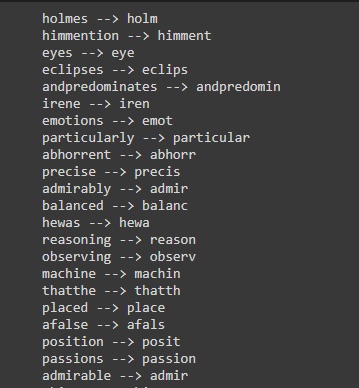
Lemmatization: it performs a morphological analysis using reference dictionaries to create equivalence classes between words.
For example, for the token “eclipses”, a stemming rule would return the term “eclips“, while through lemmatization we would get the term “eclipse“.
4/5
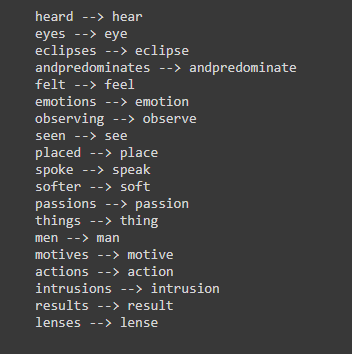
Finally, let me share a quick example on the use of these two NLP techniques (with spaCy and Python):
https://t.co/Qm0Fa4cGaV
5/5
Two of the most common TN techniques are Stemming and Lemmatization. In the next thread🧵 I will briefly tell you about them.
1/5
The aim of both methods (Stemming and Lemmatization) is the same: to reduce the inflectional forms of each word/term into a common base or root.
So what is the difference between them?
2/5
Stemming: process in which terms are transformed to their root in order to reduce the size of the vocabulary. It is carried by applying word reduction rules.
Two of the most common stemming algorithms are:
▪️Porter
▪️Snowball
3/5
Lemmatization: it performs a morphological analysis using reference dictionaries to create equivalence classes between words.
For example, for the token “eclipses”, a stemming rule would return the term “eclips“, while through lemmatization we would get the term “eclipse“.
4/5
Finally, let me share a quick example on the use of these two NLP techniques (with spaCy and Python):
https://t.co/Qm0Fa4cGaV
5/5








Since @ylecun introduced his cake analogy at NeurIPS 5 years ago, unsupervised learning and the self-supervised approach in particular, has been a major focus of @facebookai and other AI labs. Progress has been steady and remarkable almost everywhere - NLU, MT, Speech, CV, Video

Not only does this approach often lead to better performance when combined with small amount of supervision, but it offers the promise of a more inclusive and private AI, one that works for all languages and cultures and doesn’t require extensive human labeling. #ResponsibleAI
Here are pointers to some of our latest work relying on self-supervised learning:
Speech https://t.co/4K03h47kIl
CV https://t.co/FcS4QmYQMJ
NLU https://t.co/wCI2q93ybc
MT https://t.co/GIIyZ8qmZ5
Videos https://t.co/o4VWF0r0vK
Overall approach
Not only does this approach often lead to better performance when combined with small amount of supervision, but it offers the promise of a more inclusive and private AI, one that works for all languages and cultures and doesn’t require extensive human labeling. #ResponsibleAI
Here are pointers to some of our latest work relying on self-supervised learning:
Speech https://t.co/4K03h47kIl
CV https://t.co/FcS4QmYQMJ
NLU https://t.co/wCI2q93ybc
MT https://t.co/GIIyZ8qmZ5
Videos https://t.co/o4VWF0r0vK
Overall approach