Everyone tells you how important math is in machine learning.
But I believe that if you want to learn machine learning today, there are things more important than math which very few people will tell you about.
Here are 5 of them.
🧵 👇🏻
The field of machine learning has been very academic which is why there is so much emphasis on learning math for it.
But, today with the frameworks that we have, not knowing how to multiply matrices is far less of an issue than knowing how to use the tools in this list 👇🏻
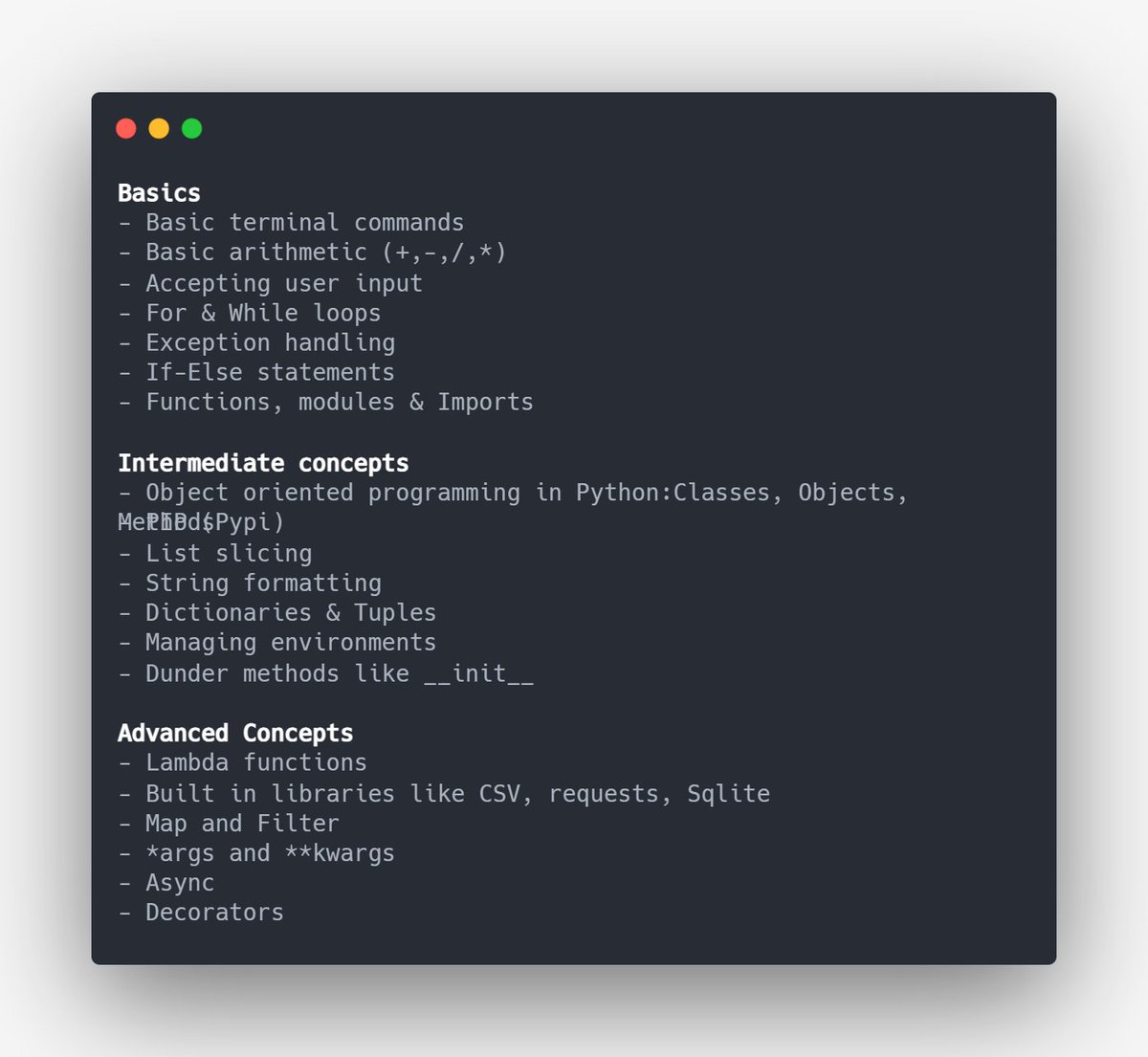
Yes, I know; you have R, Julia, and whatnot for machine learning but as of today, Python is the industry standard.
Get your data structures and algorithms right in Python because you will need them, here are some concepts worth learning 👇🏻
Let's say you're building the next big GPT-3 powered app that's going to take over the world.
You add a new feature to your app but it breaks the entire thing, what do you do now?
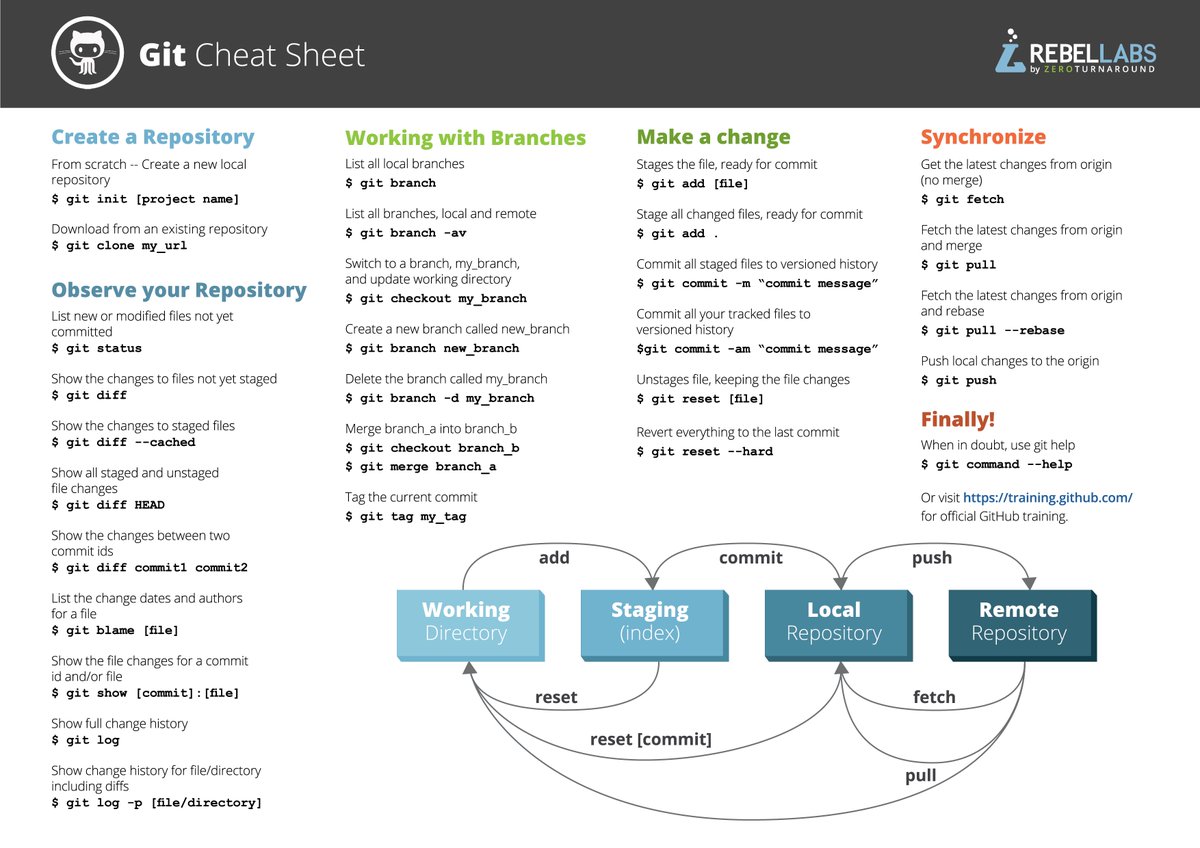
Learn Git, the ultimate version control tool.
I use this cheat sheet for all my git needs 👇🏻
You will be constantly be working on multiple packages which specific python version requirements 🐍
Virtual environments like Anaconda or Poetry will make this process much easier for you.
Who likes to see broken dependencies while running code?