
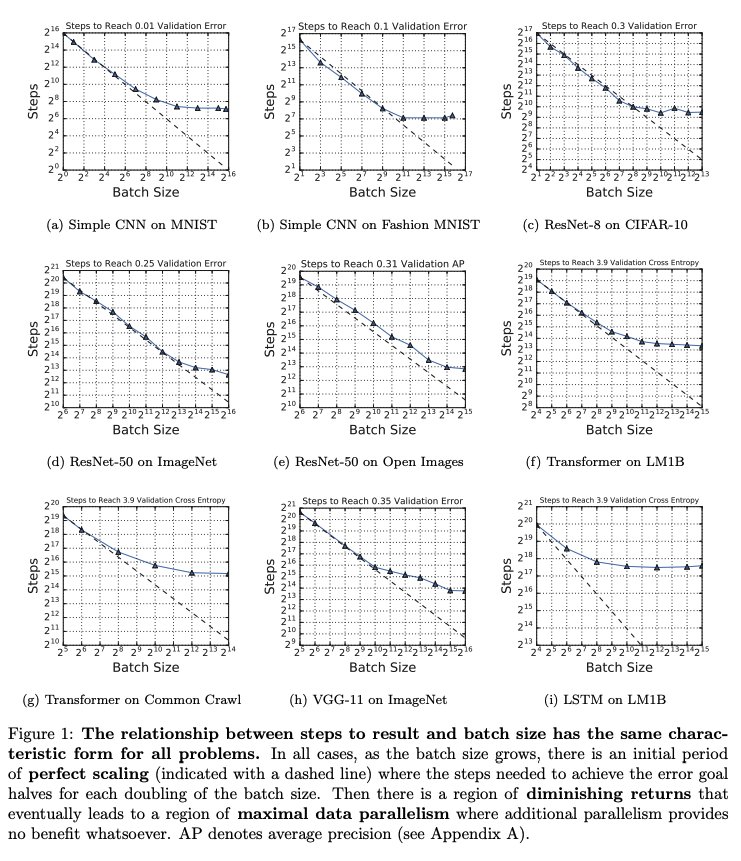
Important paper from Google on large batch optimization. They do impressively careful experiments measuring # iterations needed to achieve target validation error at various batch sizes. The main "surprise" is the lack of surprises. [thread]
https://t.co/7QIx5CFdfJ
More from Machine learning



Thanks for this incredibly helpful analysis @dgurdasani1
Two questions. 1/ Does this summarise the AZ published data :
The plan is to extend the time interval for all age groups despite it being largely untested on the over 55yrs, although the full data is not yet published
Do we have the actual numbers of over 55yr olds given a 2nd dose at c12 weeks and the accompanying efficacy data?
Not to mention the efficacy data of the full first dose over that same period?
I’d quite like to know whether I am to be a guinea pig & the ongoing risks to manage
You attached photos of excerpts from a paper. Could you attach the link?
Re Pfizer. As I understand it the most efficacious interval for dosing was investigated at the start of the trial.
Here’s the link to the
I’ve got to say that this way of making and announcing decisions is not inspiring confidence in me and I am very pro vaccination as a matter of principle, not least because my brother caught polio before vaccinations available.
Two questions. 1/ Does this summarise the AZ published data :
The plan is to extend the time interval for all age groups despite it being largely untested on the over 55yrs, although the full data is not yet published
SUMMARY: the Oxford/Astra trial examined dosing with gaps between 4-12 wks- although longer gaps appear to be limited mostly to younger participants. There was no difference reported in published data between these & efficacy from the 1st dose seems high for severe disease.
— Deepti Gurdasani (@dgurdasani1) December 31, 2020
Do we have the actual numbers of over 55yr olds given a 2nd dose at c12 weeks and the accompanying efficacy data?
Not to mention the efficacy data of the full first dose over that same period?
I’d quite like to know whether I am to be a guinea pig & the ongoing risks to manage
You attached photos of excerpts from a paper. Could you attach the link?
Re Pfizer. As I understand it the most efficacious interval for dosing was investigated at the start of the trial.
Discussions of 1 vs 2 doses suggest many are not aware of Pfizer's trials which evaluated 1 vs 2 dose immunogenicity, assessed multiple formulations (BNT162b1 BNT162b2 etc) & conducted dose-ranging in both young & old adults at the start. Saw "clear benefit of booster at day 21" pic.twitter.com/mpyxu9xFSF
— Dr Nicole E Basta (@IDEpiPhD) December 31, 2020
Here’s the link to the
I’ve got to say that this way of making and announcing decisions is not inspiring confidence in me and I am very pro vaccination as a matter of principle, not least because my brother caught polio before vaccinations available.
You May Also Like







1/OK, data mystery time.
This New York Times feature shows China with a Gini Index of less than 30, which would make it more equal than Canada, France, or the Netherlands. https://t.co/g3Sv6DZTDE
That's weird. Income inequality in China is legendary.
Let's check this number.
2/The New York Times cites the World Bank's recent report, "Fair Progress? Economic Mobility across Generations Around the World".
The report is available here:
3/The World Bank report has a graph in which it appears to show the same value for China's Gini - under 0.3.
The graph cites the World Development Indicators as its source for the income inequality data.
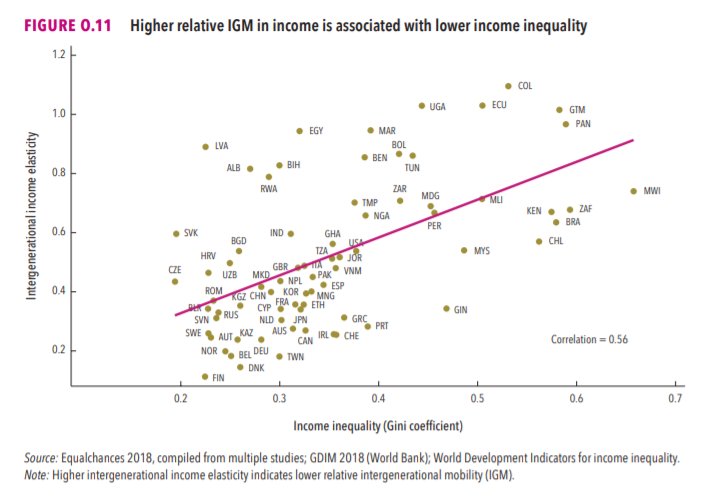
4/The World Development Indicators are available at the World Bank's website.
Here's the Gini index: https://t.co/MvylQzpX6A
It looks as if the latest estimate for China's Gini is 42.2.
That estimate is from 2012.
5/A Gini of 42.2 would put China in the same neighborhood as the U.S., whose Gini was estimated at 41 in 2013.
I can't find the <30 number anywhere. The only other estimate in the tables for China is from 2008, when it was estimated at 42.8.
This New York Times feature shows China with a Gini Index of less than 30, which would make it more equal than Canada, France, or the Netherlands. https://t.co/g3Sv6DZTDE
That's weird. Income inequality in China is legendary.
Let's check this number.
2/The New York Times cites the World Bank's recent report, "Fair Progress? Economic Mobility across Generations Around the World".
The report is available here:
3/The World Bank report has a graph in which it appears to show the same value for China's Gini - under 0.3.
The graph cites the World Development Indicators as its source for the income inequality data.
4/The World Development Indicators are available at the World Bank's website.
Here's the Gini index: https://t.co/MvylQzpX6A
It looks as if the latest estimate for China's Gini is 42.2.
That estimate is from 2012.
5/A Gini of 42.2 would put China in the same neighborhood as the U.S., whose Gini was estimated at 41 in 2013.
I can't find the <30 number anywhere. The only other estimate in the tables for China is from 2008, when it was estimated at 42.8.

Following @BAUDEGS I have experienced hateful and propagandist tweets time after time. I have been shocked that an academic community would be so reckless with their publications. So I did some research.
The question is:
Is this an official account for Bahcesehir Uni (Bau)?

Bahcesehir Uni, BAU has an official website https://t.co/ztzX6uj34V which links to their social media, leading to their Twitter account @Bahcesehir
BAU’s official Twitter account

BAU has many departments, which all have separate accounts. Nowhere among them did I find @BAUDEGS
@BAUOrganization @ApplyBAU @adayBAU @BAUAlumniCenter @bahcesehirfbe @baufens @CyprusBau @bauiisbf @bauglobal @bahcesehirebe @BAUintBatumi @BAUiletisim @BAUSaglik @bauebf @TIPBAU
Nowhere among them was @BAUDEGS to find

The question is:
Is this an official account for Bahcesehir Uni (Bau)?
Bahcesehir Uni, BAU has an official website https://t.co/ztzX6uj34V which links to their social media, leading to their Twitter account @Bahcesehir
BAU’s official Twitter account
BAU has many departments, which all have separate accounts. Nowhere among them did I find @BAUDEGS
@BAUOrganization @ApplyBAU @adayBAU @BAUAlumniCenter @bahcesehirfbe @baufens @CyprusBau @bauiisbf @bauglobal @bahcesehirebe @BAUintBatumi @BAUiletisim @BAUSaglik @bauebf @TIPBAU
Nowhere among them was @BAUDEGS to find





"I lied about my basic beliefs in order to keep a prestigious job. Now that it will be zero-cost to me, I have a few things to say."
We know that elite institutions like the one Flier was in (partial) charge of rely on irrelevant status markers like private school education, whiteness, legacy, and ability to charm an old white guy at an interview.
Harvard's discriminatory policies are becoming increasingly well known, across the political spectrum (see, e.g., the recent lawsuit on discrimination against East Asian applications.)
It's refreshing to hear a senior administrator admits to personally opposing policies that attempt to remedy these basic flaws. These are flaws that harm his institution's ability to do cutting-edge research and to serve the public.
Harvard is being eclipsed by institutions that have different ideas about how to run a 21st Century institution. Stanford, for one; the UC system; the "public Ivys".
As a dean of a major academic institution, I could not have said this. But I will now. Requiring such statements in applications for appointments and promotions is an affront to academic freedom, and diminishes the true value of diversity, equity of inclusion by trivializing it. https://t.co/NfcI5VLODi
— Jeffrey Flier (@jflier) November 10, 2018
We know that elite institutions like the one Flier was in (partial) charge of rely on irrelevant status markers like private school education, whiteness, legacy, and ability to charm an old white guy at an interview.
Harvard's discriminatory policies are becoming increasingly well known, across the political spectrum (see, e.g., the recent lawsuit on discrimination against East Asian applications.)
It's refreshing to hear a senior administrator admits to personally opposing policies that attempt to remedy these basic flaws. These are flaws that harm his institution's ability to do cutting-edge research and to serve the public.
Harvard is being eclipsed by institutions that have different ideas about how to run a 21st Century institution. Stanford, for one; the UC system; the "public Ivys".