

Last up in Privacy Tech for #enigma2021, @xchatty speaking about "IMPLEMENTING DIFFERENTIAL PRIVACY FOR THE 2020
* Data users expect consistent data releases
* Some people call synthetic data "fake data" like
"fake news"
* It's not clear what "quality assurance" and "data exploration" means in a DP framework

* required to collect it by the constitution
* but required to maintain privacy by law
* differential privacy is open and we can talk about privacy loss/accuracy tradeoff
* swapping assumed limitations of the attackers (e.g. limited computational power)
Change in the meaning of "privacy" as relative -- it requires a lot of explanation and overcoming organizational barriers.
* different groups at the Census thought that meant different things
* before, states were processed as they came in. Differential privacy requires everything be computed on at once
* required a lot more computing power
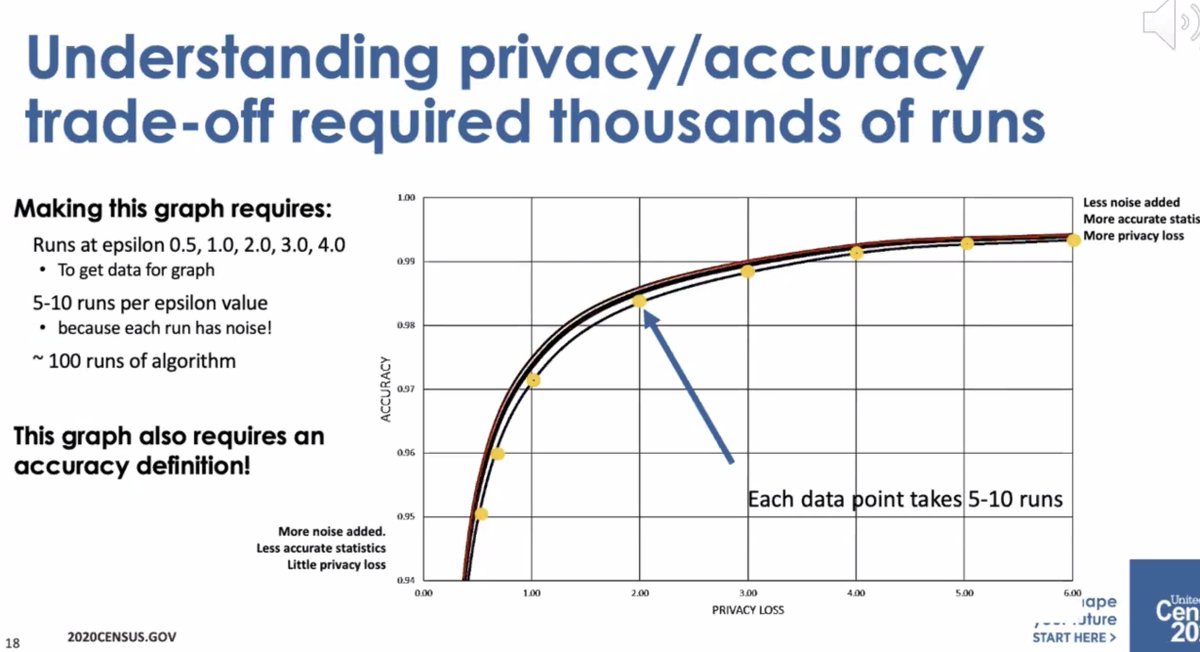
* initial implementation was by Dan Kiefer, who took a sabbatical
* expanded team to with Simson and others
* 2018 end to end test
* then got to move to AWS Elastic compute... but the monitoring wasn't good enough and had to create their own dashboard to track execution
* it wasn't a small amount of compute
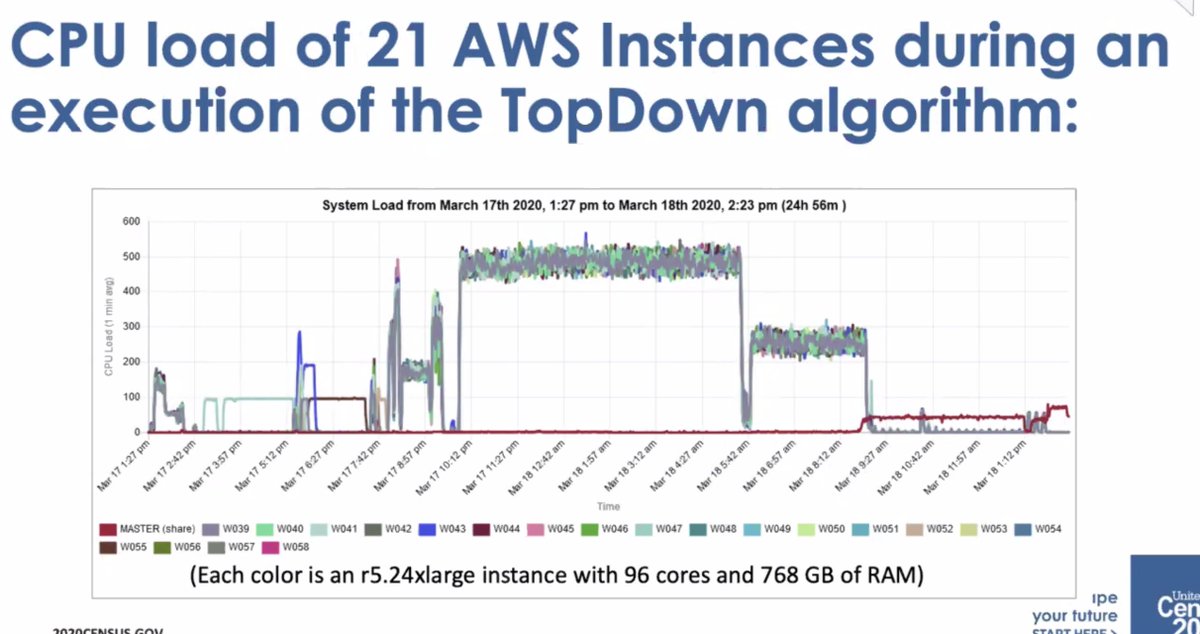
* ... it wasn't well-received by the data users who thought there was too much error
If you avoid that, you might add bias to the data. How to avoid that? Let some data users get access to the measurement files [I don't follow]

More from Lea Kissner




More from Tech


"I really want to break into Product Management"
make products.
"If only someone would tell me how I can get a startup to notice me."
Make Products.
"I guess it's impossible and I'll never break into the industry."
MAKE PRODUCTS.
Courtesy of @edbrisson's wonderful thread on breaking into comics – https://t.co/TgNblNSCBj – here is why the same applies to Product Management, too.
There is no better way of learning the craft of product, or proving your potential to employers, than just doing it.
You do not need anybody's permission. We don't have diplomas, nor doctorates. We can barely agree on a single standard of what a Product Manager is supposed to do.
But – there is at least one blindingly obvious industry consensus – a Product Manager makes Products.
And they don't need to be kept at the exact right temperature, given endless resource, or carefully protected in order to do this.
They find their own way.
make products.
"If only someone would tell me how I can get a startup to notice me."
Make Products.
"I guess it's impossible and I'll never break into the industry."
MAKE PRODUCTS.
Courtesy of @edbrisson's wonderful thread on breaking into comics – https://t.co/TgNblNSCBj – here is why the same applies to Product Management, too.
"I really want to break into comics"
— Ed Brisson (@edbrisson) December 4, 2018
make comics.
"If only someone would tell me how I can get an editor to notice me."
Make Comics.
"I guess it's impossible and I'll never break into the industry."
MAKE COMICS.
There is no better way of learning the craft of product, or proving your potential to employers, than just doing it.
You do not need anybody's permission. We don't have diplomas, nor doctorates. We can barely agree on a single standard of what a Product Manager is supposed to do.
But – there is at least one blindingly obvious industry consensus – a Product Manager makes Products.
And they don't need to be kept at the exact right temperature, given endless resource, or carefully protected in order to do this.
They find their own way.






You May Also Like







THREAD: 12 Things Everyone Should Know About IQ
1. IQ is one of the most heritable psychological traits – that is, individual differences in IQ are strongly associated with individual differences in genes (at least in fairly typical modern environments). https://t.co/3XxzW9bxLE
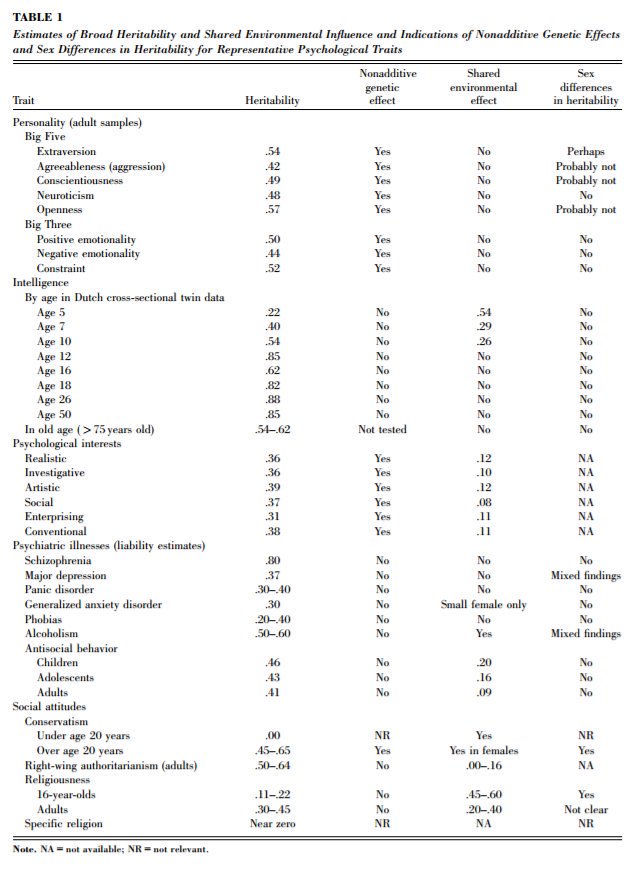
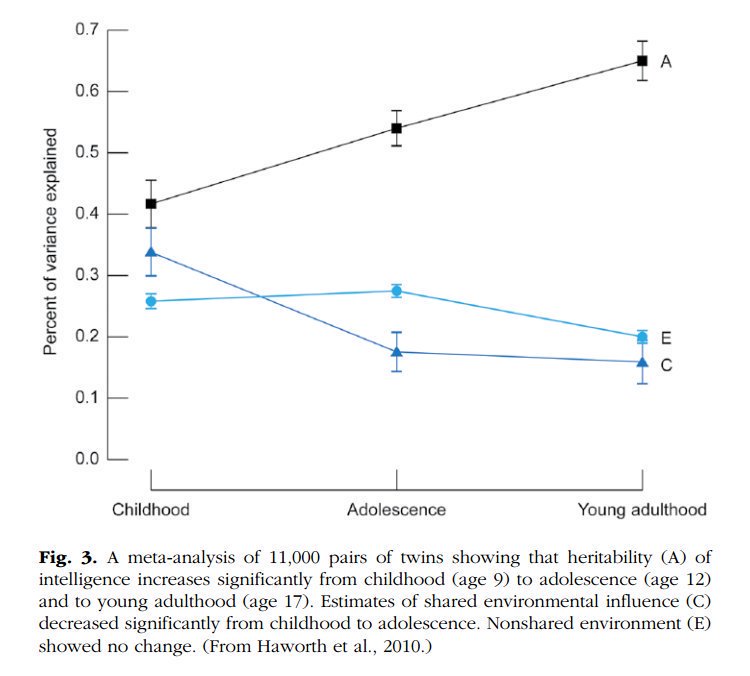
2. The heritability of IQ *increases* from childhood to adulthood. Meanwhile, the effect of the shared environment largely fades away. In other words, when it comes to IQ, nature becomes more important as we get older, nurture less. https://t.co/UqtS1lpw3n
3. IQ scores have been increasing for the last century or so, a phenomenon known as the Flynn effect. https://t.co/sCZvCst3hw (N ≈ 4 million)
(Note that the Flynn effect shows that IQ isn't 100% genetic; it doesn't show that it's 100% environmental.)

4. IQ predicts many important real world outcomes.
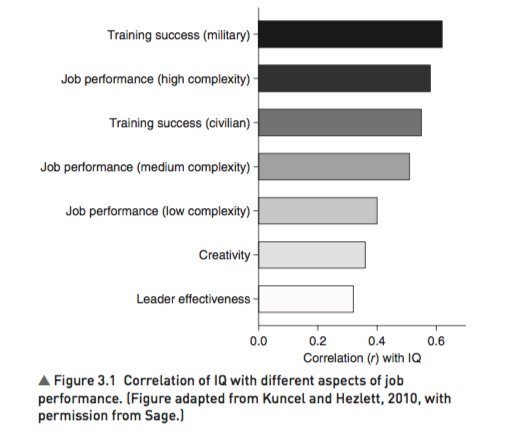
For example, though far from perfect, IQ is the single-best predictor of job performance we have – much better than Emotional Intelligence, the Big Five, Grit, etc. https://t.co/rKUgKDAAVx https://t.co/DWbVI8QSU3
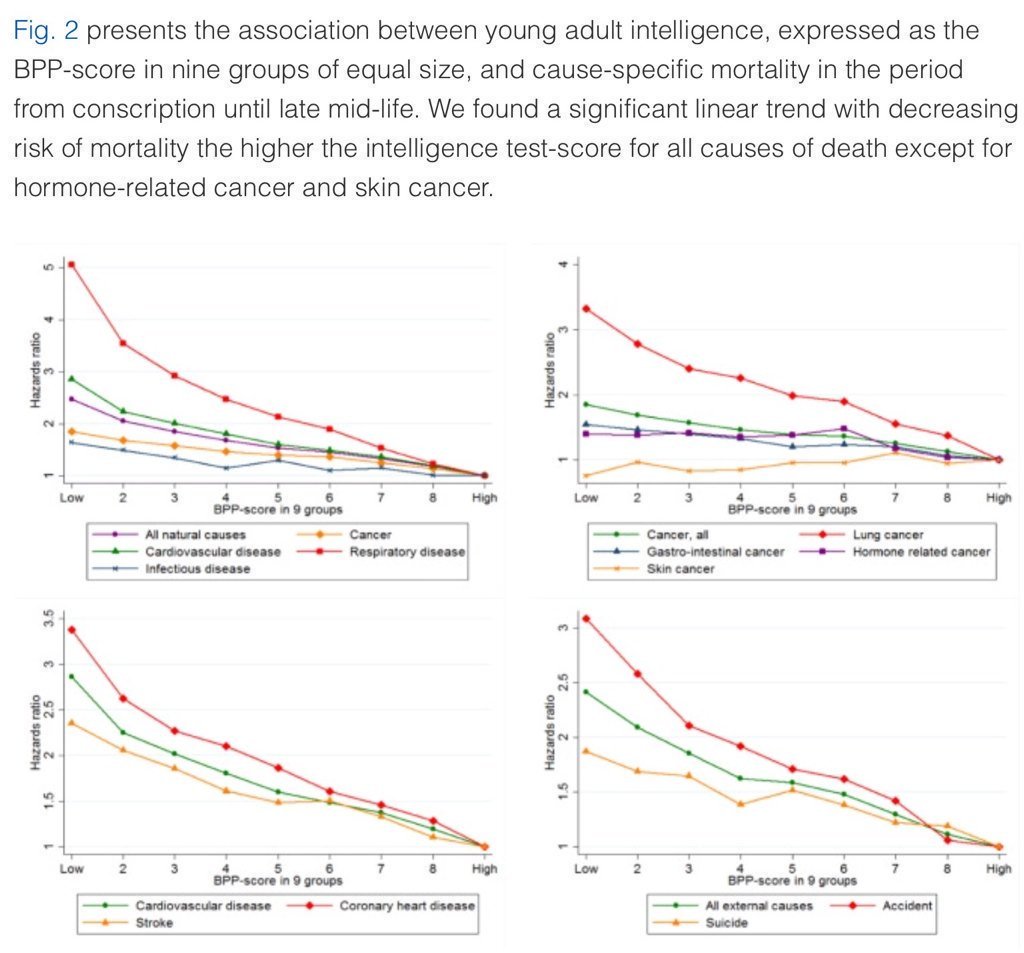
5. Higher IQ is associated with a lower risk of death from most causes, including cardiovascular disease, respiratory disease, most forms of cancer, homicide, suicide, and accident. https://t.co/PJjGNyeQRA (N = 728,160)
1. IQ is one of the most heritable psychological traits – that is, individual differences in IQ are strongly associated with individual differences in genes (at least in fairly typical modern environments). https://t.co/3XxzW9bxLE
2. The heritability of IQ *increases* from childhood to adulthood. Meanwhile, the effect of the shared environment largely fades away. In other words, when it comes to IQ, nature becomes more important as we get older, nurture less. https://t.co/UqtS1lpw3n
3. IQ scores have been increasing for the last century or so, a phenomenon known as the Flynn effect. https://t.co/sCZvCst3hw (N ≈ 4 million)
(Note that the Flynn effect shows that IQ isn't 100% genetic; it doesn't show that it's 100% environmental.)
4. IQ predicts many important real world outcomes.
For example, though far from perfect, IQ is the single-best predictor of job performance we have – much better than Emotional Intelligence, the Big Five, Grit, etc. https://t.co/rKUgKDAAVx https://t.co/DWbVI8QSU3
5. Higher IQ is associated with a lower risk of death from most causes, including cardiovascular disease, respiratory disease, most forms of cancer, homicide, suicide, and accident. https://t.co/PJjGNyeQRA (N = 728,160)






I'm going to do two history threads on Ethiopia, one on its ancient history, one on its modern story (1800 to today). 🇪🇹
I'll begin with the ancient history ... and it goes way back. Because modern humans - and before that, the ancestors of humans - almost certainly originated in Ethiopia. 🇪🇹 (sub-thread):
The first likely historical reference to Ethiopia is ancient Egyptian records of trade expeditions to the "Land of Punt" in search of gold, ebony, ivory, incense, and wild animals, starting in c 2500 BC 🇪🇹
Ethiopians themselves believe that the Queen of Sheba, who visited Israel's King Solomon in the Bible (c 950 BC), came from Ethiopia (not Yemen, as others believe). Here she is meeting Solomon in a stain-glassed window in Addis Ababa's Holy Trinity Church. 🇪🇹

References to the Queen of Sheba are everywhere in Ethiopia. The national airline's frequent flier miles are even called "ShebaMiles". 🇪🇹

I'll begin with the ancient history ... and it goes way back. Because modern humans - and before that, the ancestors of humans - almost certainly originated in Ethiopia. 🇪🇹 (sub-thread):
The famous \u201cLucy\u201d, an early ancestor of modern humans (Australopithecus) that lived 3.2 million years ago, and was discovered in 1974 in Ethiopia, displayed in the national museum in Addis Ababa \U0001f1ea\U0001f1f9 pic.twitter.com/N3oWqk1SW2
— Patrick Chovanec (@prchovanec) November 9, 2018
The first likely historical reference to Ethiopia is ancient Egyptian records of trade expeditions to the "Land of Punt" in search of gold, ebony, ivory, incense, and wild animals, starting in c 2500 BC 🇪🇹
Ethiopians themselves believe that the Queen of Sheba, who visited Israel's King Solomon in the Bible (c 950 BC), came from Ethiopia (not Yemen, as others believe). Here she is meeting Solomon in a stain-glassed window in Addis Ababa's Holy Trinity Church. 🇪🇹
References to the Queen of Sheba are everywhere in Ethiopia. The national airline's frequent flier miles are even called "ShebaMiles". 🇪🇹

A brief analysis and comparison of the CSS for Twitter's PWA vs Twitter's legacy desktop website. The difference is dramatic and I'll touch on some reasons why.
Legacy site *downloads* ~630 KB CSS per theme and writing direction.
6,769 rules
9,252 selectors
16.7k declarations
3,370 unique declarations
44 media queries
36 unique colors
50 unique background colors
46 unique font sizes
39 unique z-indices
https://t.co/qyl4Bt1i5x

PWA *incrementally generates* ~30 KB CSS that handles all themes and writing directions.
735 rules
740 selectors
757 declarations
730 unique declarations
0 media queries
11 unique colors
32 unique background colors
15 unique font sizes
7 unique z-indices
https://t.co/w7oNG5KUkJ

The legacy site's CSS is what happens when hundreds of people directly write CSS over many years. Specificity wars, redundancy, a house of cards that can't be fixed. The result is extremely inefficient and error-prone styling that punishes users and developers.
The PWA's CSS is generated on-demand by a JS framework that manages styles and outputs "atomic CSS". The framework can enforce strict constraints and perform optimisations, which is why the CSS is so much smaller and safer. Style conflicts and unbounded CSS growth are avoided.
Legacy site *downloads* ~630 KB CSS per theme and writing direction.
6,769 rules
9,252 selectors
16.7k declarations
3,370 unique declarations
44 media queries
36 unique colors
50 unique background colors
46 unique font sizes
39 unique z-indices
https://t.co/qyl4Bt1i5x
PWA *incrementally generates* ~30 KB CSS that handles all themes and writing directions.
735 rules
740 selectors
757 declarations
730 unique declarations
0 media queries
11 unique colors
32 unique background colors
15 unique font sizes
7 unique z-indices
https://t.co/w7oNG5KUkJ
The legacy site's CSS is what happens when hundreds of people directly write CSS over many years. Specificity wars, redundancy, a house of cards that can't be fixed. The result is extremely inefficient and error-prone styling that punishes users and developers.
The PWA's CSS is generated on-demand by a JS framework that manages styles and outputs "atomic CSS". The framework can enforce strict constraints and perform optimisations, which is why the CSS is so much smaller and safer. Style conflicts and unbounded CSS growth are avoided.