Who is this course for?
- 💻 Software engineers / Data scientists looking to learn how to responsibly create ML systems.
- 🎓 College grads looking to learn the practical skills they'll need for the industry.
- 🚀 Product Managers who want to develop a technical foundation.
We start with lessons on the fundamentals of ML through intuitive explanations, clean code and visualizations.
📚 Foundations
- Python (variables, functions, classes, decorators)
- NumPy (numerical analysis)
- Pandas (data analysis)
- PyTorch (operations, gradients)
Then we dive into implementing basic ML algorithms 1⃣ from scratch then 2⃣ in PyTorch. Starting from simple models → complex models.
📈 Modeling
- Linear Regression
- Logistic Regression
- Neural Networks
- Data Quality (⚠️ very important)
- Utilities (for loading and training)
We wrap up the fundamentals by implementing deep learning algorithms in PyTorch.
🤖 Deep Learning
- CNNs
- Embeddings
- RNNs
- Transformers
💡 We motivate the need for specific architectures and additional complexity as we implement each method.
The first MLOps lessons are on the Product development and iteration cycle.
📦 Product
- Identify the core objective.
- Design a solution with constraints.
- Evaluation strategies that avoid bias.
- Iterate via feedback and motivate adding complexity.
Next we dive into exploring and transforming our data.
🔢 Data
- Labeling (data worth modeling, active learning)
- Preprocessing (prepare + transform)
- Exploration (answering questions)
- Splitting (multi-label classification)
- Augmentation (nlpaug, transformation functions)
📈 Modeling
- Baselines (simple → complex)
- Evaluation (overall, slices, generated)
- Experiment tracking (tracking, viewing and loading)
- Optimization (sampling + pruning)
💡 These aren't just tutorial code snippets. We implement everything with clean and tested code.
Next, we move our work from notebooks to scripts.
📝 Scripting
- Organization
- Packaging (setup + virtualenv)
- Documentation (auto)
- Logging (logger, handler, formatter)
- Styling (black, isort, flake8)
- Makefile
💻 All of this makes for a very calm developing experience.
Now we're ready to wrap our application via various interfaces.
📦 Interfaces
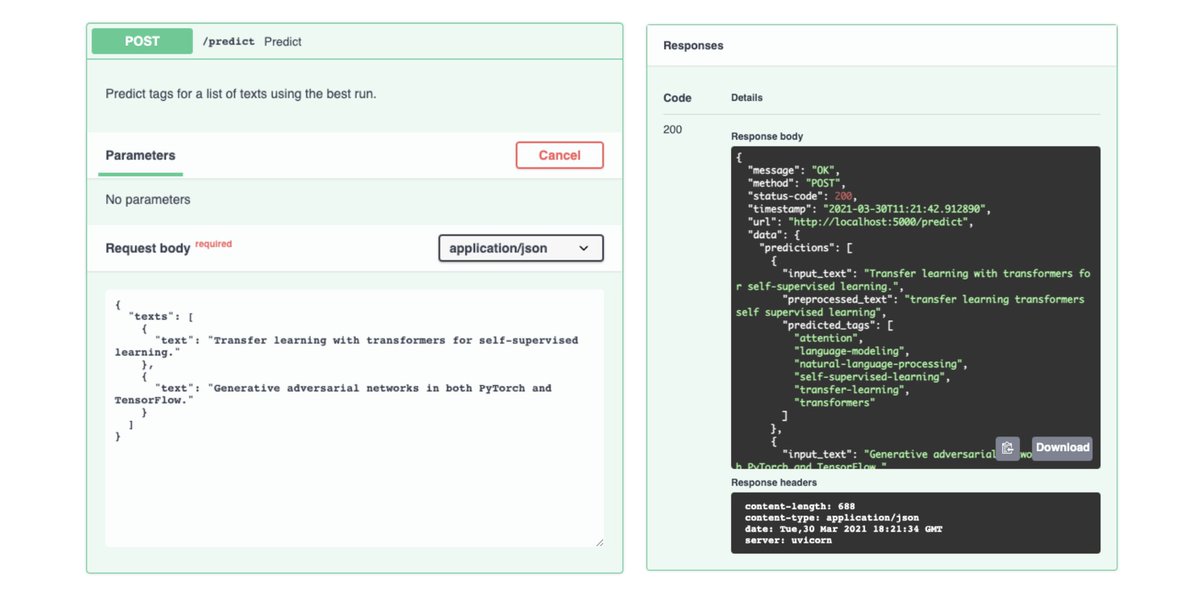
- Command-line (CLI)
- RESTful API with FastAPI (design, schemas, validation)
💡 These interfaces allow us to quickly execute both internal (training, testing, etc.) and external (inference) tasks.
Throughout development, we've been testing not only our code but also our data and models.
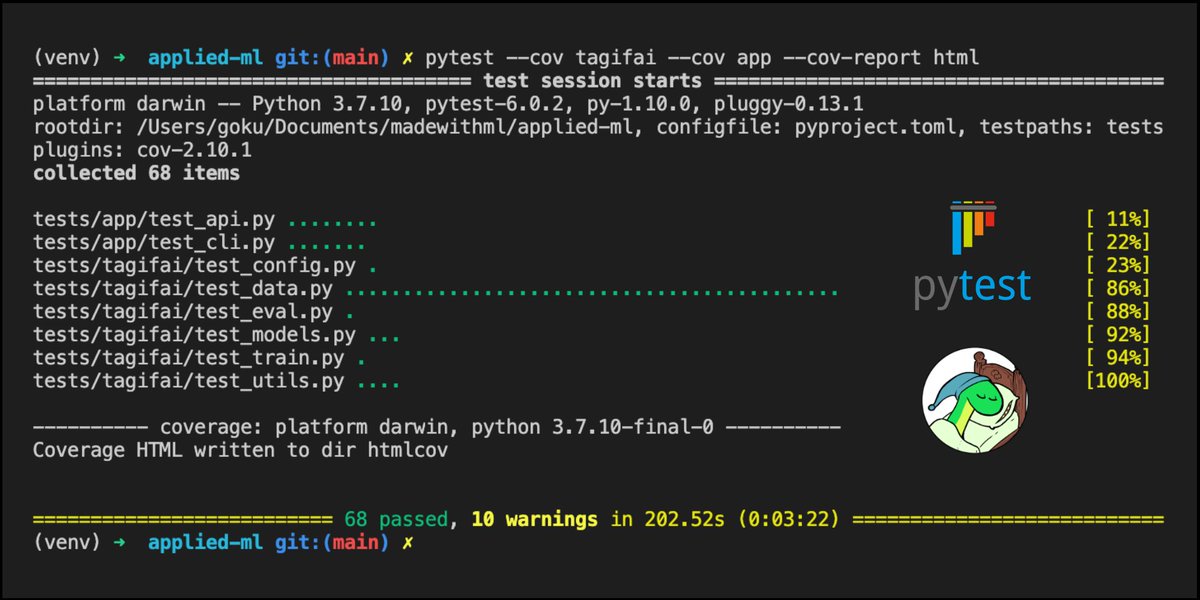
✅ Testing
- Test types, coverage, best practices
- Pytest fixtures, markers, parametrize
- Test data w/ Great Expectations
- Test models via slicing functions
- Behavioral tests
We want to ensure that our work is entirely reproducible by anyone.
♻️ Reproducibility
- Git basics via workflows (dev, inspect, merge, etc.)
- Pre-commit hooks (+ custom local)
- Versioning code + config + data = models via DVC
- Containerization via Docker
Next, we want to be able to showcase our work and enable interaction via
@streamlit. 📊 Dashboard:
- Data: annotation, EDA, preprocessing
- Performance: overall, slices, regressions
- Inference: intermediate & final outputs
- Inspection: labeling (FP), weaknesses (FN)
Then, we wrap all of the CI/CD workflows we’ve created with
@GitHub Actions:
🔄 CI/CD workflows
- Workflow components (events, runners, jobs)
- Testing Actions locally using Act
- Best practices (ex. caching)
- ML Actions (Great Expectations checkpoints, DVC CML)
Next, we explore the infra needed to deploy & serve ML applications.
🛠️ Infrastructure:
- Serving (batch, real-time)
- Processing (batch, stream)
- Learning (offline, online)
- Testing (AB, canary, shadow)
- Optimization (prune, quantize, distill)
- Methods (K8s, serverless)
We ensure the health of our ML system with appropriate monitoring.
🔍 Monitoring:
- identifying drift (data, target, concept)
- measuring drift on uni/multivariate data via
- reducers (PCA, UAE)
- detectors (chi^2, KS, MMD)
- solutions (not always retraining)
Finally, we connect our DataOps & MLOps workflows in our ML systems.
▶️ Workflow orchestration w/
@ApacheAirflow - DAGs
- Scheduler
- Tasks
- Operators
- Runs
🏪 Feature stores w/
@feast_dev - data ingestion
- feature definitions
- historical/online features
Over the past 7 years, I've worked on ML and product at
@Apple, health tech startups and ran my own venture in the rideshare space. I've worked with brilliant developers and managers and learned how to responsibly develop and iterate on ML systems across various industries.
I currently work closely with early-stage & mid-sized companies in helping them deliver value with ML while diving into the best & bespoke practices of this rapidly evolving space. I want to share that knowledge with the rest of the world so we can accelerate overall progress.
ML is not a separate industry, instead, it's a powerful way of thinking about data. The foundations we've laid out will continue to hold but the methods and avenues of application will evolve. So these lessons are by no means "complete" and we'll continue to keep them up-to-date.
Even more exciting content coming later this year, so stay tuned!
- 🏆 Among top MLOps repos on GitHub:
https://t.co/gsYawqTq6U - 🛠️ A highly recommended resource used by industry:
https://t.co/pcMd8jZfo5 - ❤️ 30K+ community members:
https://t.co/CswgmDZhCq