
1 There's a chasm between an NLP technology that works well in the research lab and something that works for applications that real people use. This was eye-opening when I started my career, and every time I talk to an NLP engineer at @textio, it continues to strike me even now.
More from Machine learning





This is a Twitter series on #FoundationsOfML.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.
❓ Today, I want to start discussing the different types of Machine Learning flavors we can find.
This is a very high-level overview. In later threads, we'll dive deeper into each paradigm... 👇🧵
Last time we talked about how Machine Learning works.
Basically, it's about having some source of experience E for solving a given task T, that allows us to find a program P which is (hopefully) optimal w.r.t. some metric
I'm starting a Twitter series on #FoundationsOfML. Today, I want to answer this simple question.
— Alejandro Piad Morffis (@AlejandroPiad) January 12, 2021
\u2753 What is Machine Learning?
This is my preferred way of explaining it... \U0001f447\U0001f9f5
According to the nature of that experience, we can define different formulations, or flavors, of the learning process.
A useful distinction is whether we have an explicit goal or desired output, which gives rise to the definitions of 1️⃣ Supervised and 2️⃣ Unsupervised Learning 👇
1️⃣ Supervised Learning
In this formulation, the experience E is a collection of input/output pairs, and the task T is defined as a function that produces the right output for any given input.
👉 The underlying assumption is that there is some correlation (or, in general, a computable relation) between the structure of an input and its corresponding output and that it is possible to infer that function or mapping from a sufficiently large number of examples.

Really enjoyed digging into recent innovations in the football analytics industry.
>10 hours of interviews for this w/ a dozen or so of top firms in the game. Really grateful to everyone who gave up time & insights, even those that didnt make final cut 🙇♂️ https://t.co/9YOSrl8TdN
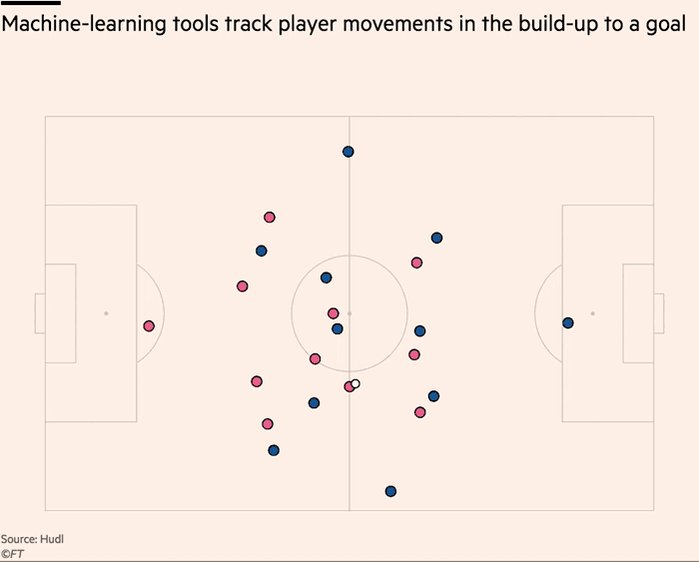
For avoidance of doubt, leading tracking analytics firms are now well beyond voronoi diagrams, using more granular measures to assess control and value of space.
This @JaviOnData & @LukeBornn paper from 2018 referenced in the piece demonstrates one method https://t.co/Hx8XTUMpJ5

Bit of this that I nerded out on the most is "ghosting" — technique used by @counterattack9 & co @stats_insights, among others.
Deep learning models predict how specific players — operating w/in specific setups — will move & execute actions. A paper here: https://t.co/9qrKvJ70EN
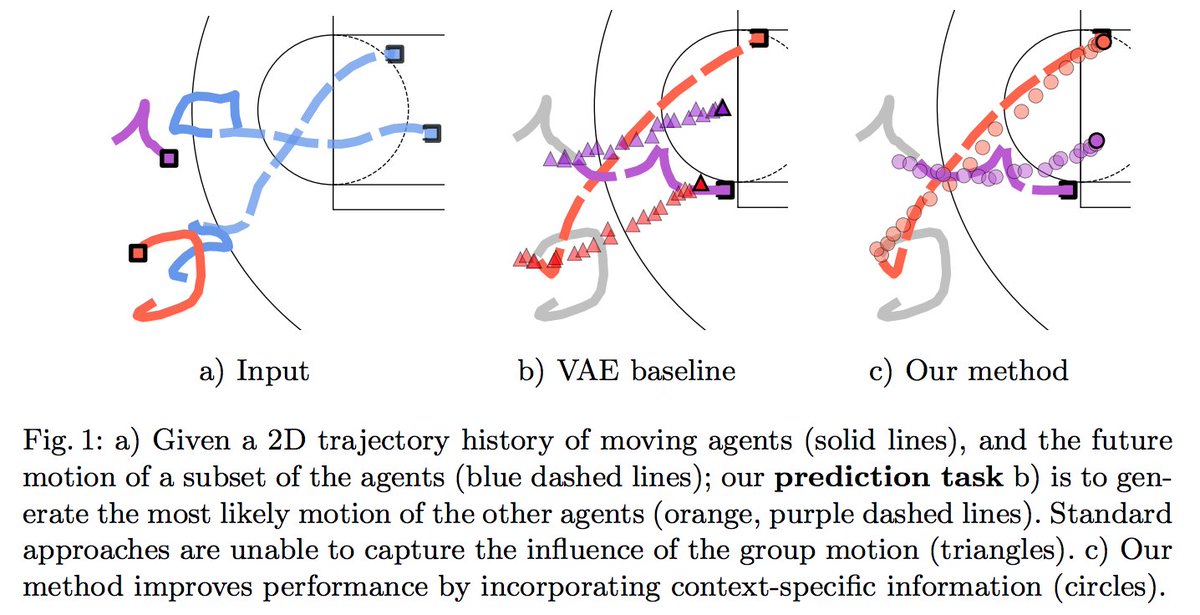
So many use-cases:
1/ Quickly & automatically spot situations where opponent's defence is abnormally vulnerable. Drill those to death in training.
2/ Swap target player B in for current player A, and simulate. How does target player strengthen/weaken team? In specific situations?
>10 hours of interviews for this w/ a dozen or so of top firms in the game. Really grateful to everyone who gave up time & insights, even those that didnt make final cut 🙇♂️ https://t.co/9YOSrl8TdN
For avoidance of doubt, leading tracking analytics firms are now well beyond voronoi diagrams, using more granular measures to assess control and value of space.
This @JaviOnData & @LukeBornn paper from 2018 referenced in the piece demonstrates one method https://t.co/Hx8XTUMpJ5
Bit of this that I nerded out on the most is "ghosting" — technique used by @counterattack9 & co @stats_insights, among others.
Deep learning models predict how specific players — operating w/in specific setups — will move & execute actions. A paper here: https://t.co/9qrKvJ70EN
So many use-cases:
1/ Quickly & automatically spot situations where opponent's defence is abnormally vulnerable. Drill those to death in training.
2/ Swap target player B in for current player A, and simulate. How does target player strengthen/weaken team? In specific situations?












