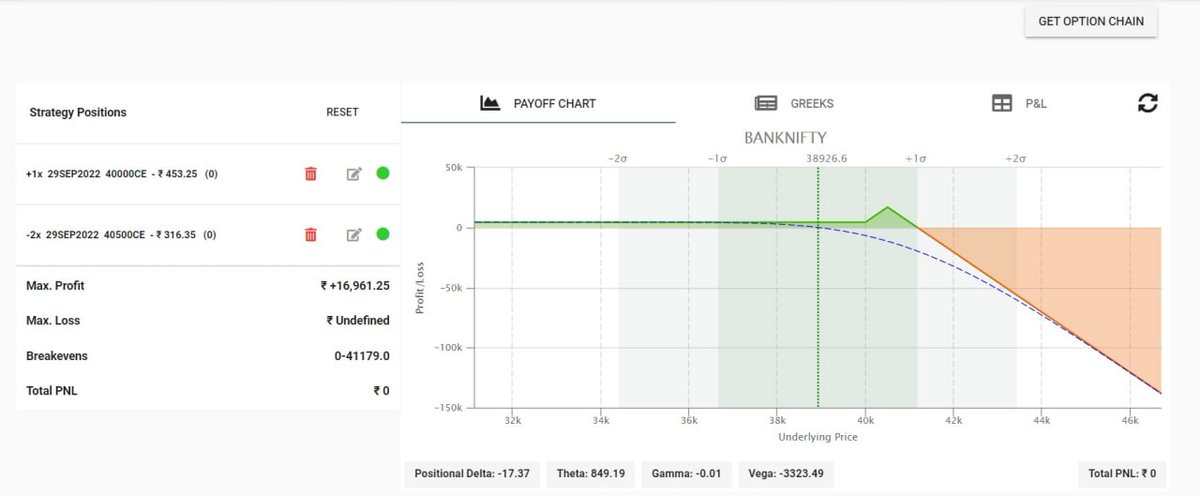
Buy x 1 = 40000 CE
Sell x 2 = 40500 CE
How to be 5x more productive.
— Ben Meer (@SystemSunday) August 1, 2022
A best-selling author\u2019s 3-3-3 Method:
I'm increasingly interested in the idea of "personal moats" in the context of careers.
— Erik Torenberg (@eriktorenberg) November 22, 2018
Moats should be:
- Hard to learn and hard to do (but perhaps easier for you)
- Skills that are rare and valuable
- Legible
- Compounding over time
- Unique to your own talents & interests https://t.co/bB3k1YcH5b
People talk about \u201cpassive income\u201d a lot but not about \u201cpassive social capital\u201d or \u201cpassive networking\u201d or \u201cpassive knowledge gaining\u201d but that\u2019s what you can architect if you have a thing and it grows over time without intensive constant effort to sustain it
— Andrew Chen (@andrewchen) November 22, 2018
Things that look like moats but likely aren\u2019t or may fade:
— Erik Torenberg (@eriktorenberg) November 22, 2018
- Proprietary networks
- Being something other than one of the best at any tournament style-game
- Many "awards"
- Twitter followers or general reach without "respect"
- Anything that depends on information asymmetry https://t.co/abjxesVIh9