
This jump is surprising and I’d like to understand better why it happens at all.
Thread on @AnthropicAI's cool new paper on how large models are both predictable (scaling laws) and surprising (capability jumps).
1. That there’s a capability jump in 3-digit addition for GPT3 (left) is unsurprising. Good challenge to better predict when such jump will occur.
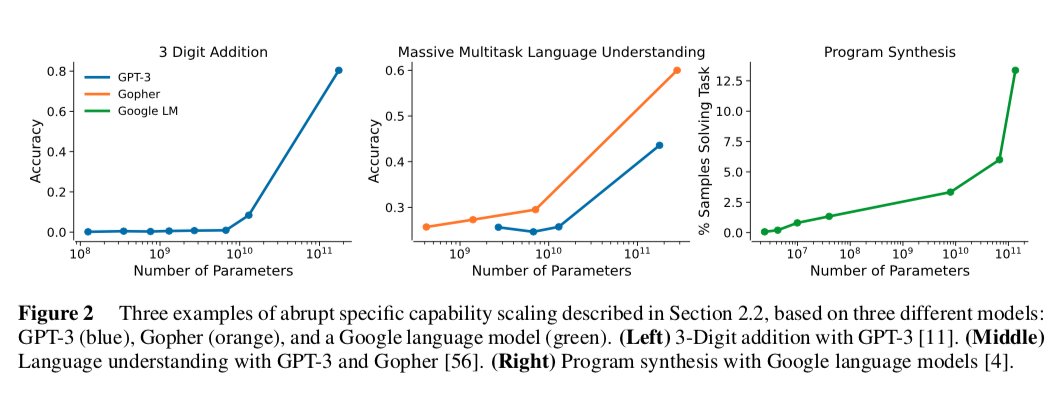
This jump is surprising and I’d like to understand better why it happens at all.
Related work:
1. @gwern's list of capability jumps and classic article on scaling
https://t.co/C8qljJa13A
https://t.co/er791mhbjP
3. Lukas Finnveden's post on GPT-n extrapolation /scaling on different task shttps://www.lesswrong.com/posts/k2SNji3jXaLGhBeYP/extrapolating-gpt-n-performance
More from All














How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)

Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)
Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)




You May Also Like









✨📱 iOS 12.1 📱✨
🗓 Release date: October 30, 2018
📝 New Emojis: 158
https://t.co/bx8XjhiCiB

New in iOS 12.1: 🥰 Smiling Face With 3 Hearts https://t.co/6eajdvueip

New in iOS 12.1: 🥵 Hot Face https://t.co/jhTv1elltB

New in iOS 12.1: 🥶 Cold Face https://t.co/EIjyl6yZrF

New in iOS 12.1: 🥳 Partying Face https://t.co/p8FDNEQ3LJ

🗓 Release date: October 30, 2018
📝 New Emojis: 158
https://t.co/bx8XjhiCiB
New in iOS 12.1: 🥰 Smiling Face With 3 Hearts https://t.co/6eajdvueip
New in iOS 12.1: 🥵 Hot Face https://t.co/jhTv1elltB
New in iOS 12.1: 🥶 Cold Face https://t.co/EIjyl6yZrF
New in iOS 12.1: 🥳 Partying Face https://t.co/p8FDNEQ3LJ