"A Data-Based Perspective on Transfer Learning"
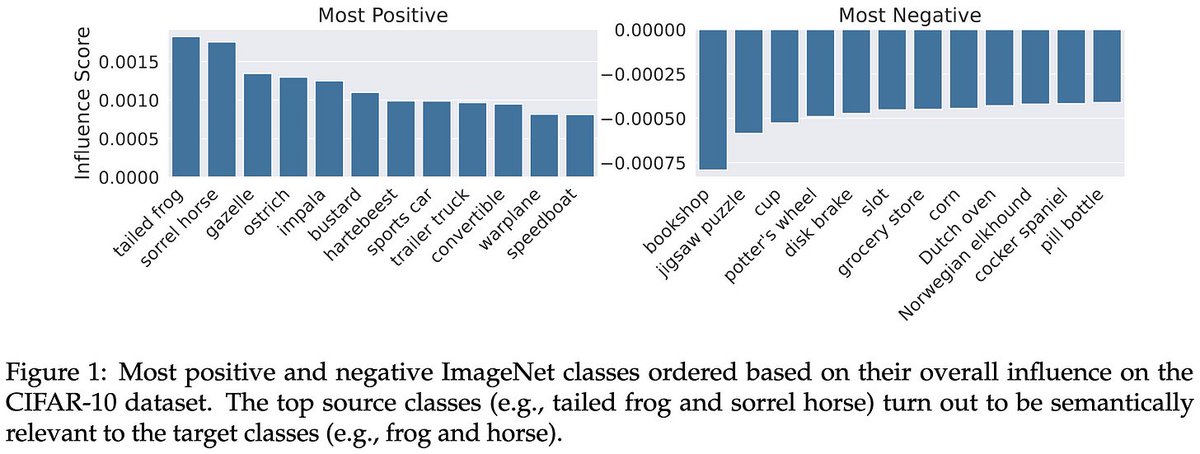
Different classes in a pretraining dataset can have different effects on downstream accuracy. And you can use this to your advantage. [1/9]
They assess these effects using a simple algorithm that trains different models on different subsets of the data and looks at both the class counts and the predictions for each model on each downstream sample. [2/9]
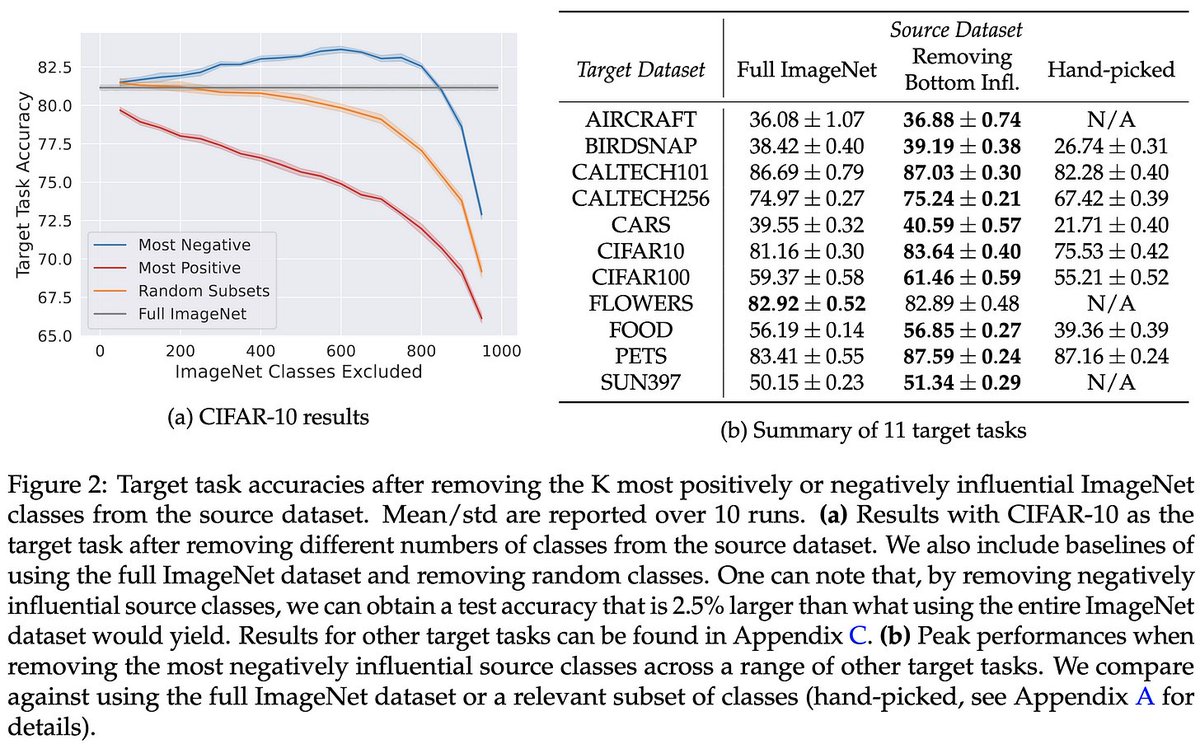
Using their scoring function, you can intelligently remove subsets of classes from the pretraining dataset in order to significantly raise downstream accuracy. [3/9]
Another use of their method is identifying more granular subpopulations than what a downstream task has annotated. E.g., you can find which CIFAR-10 images look most like ostriches even though CIFAR-10 only has the label “bird”. [4/9]
You can also use a similar idea to understand model failure modes or identify data leakage. [5/9]