I’m excited to share our new paper on HyperTransformers, a novel architecture for few-shot learning able to generate the weights of a CNN directly from a given support set. 🧵👇
📜: https://t.co/vcm67G6P6t with Andrey Zhmoginov and Mark Sandler.
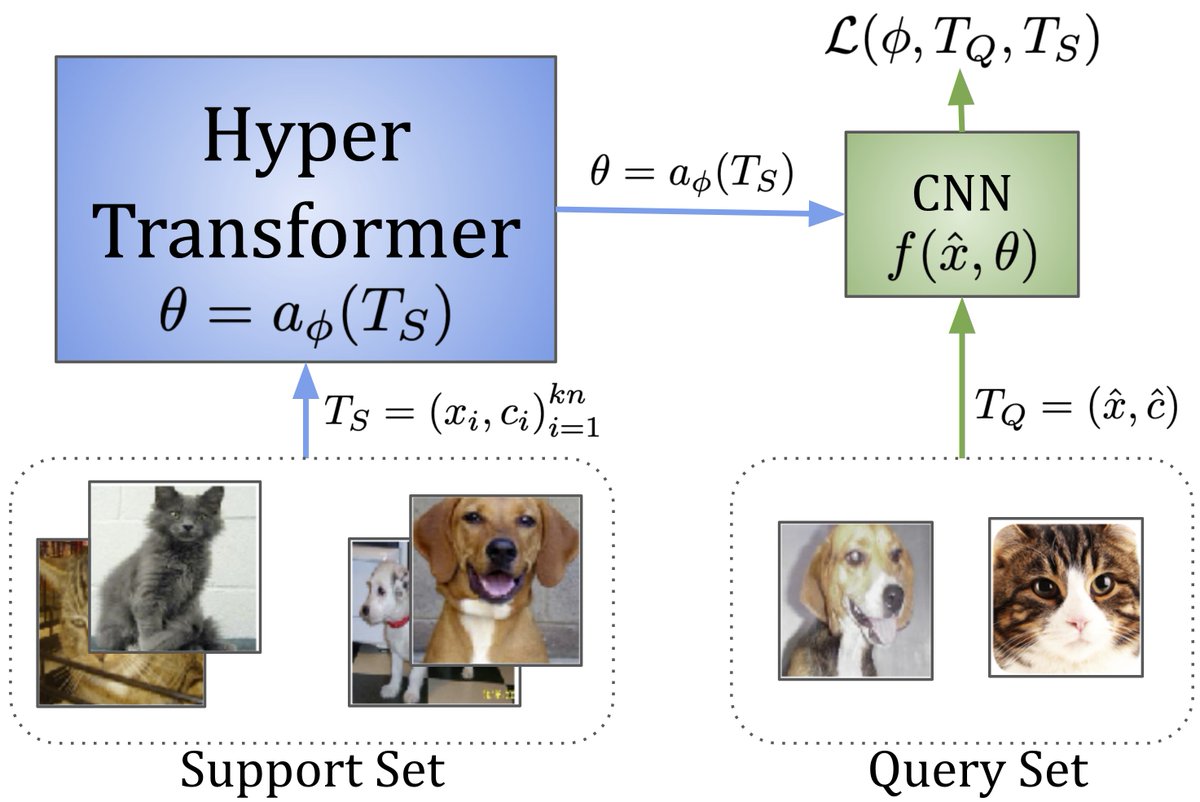
2) We train a transformer model to `convert` a few-shot task description into a small CNN network specialized in solving it on new images.
3) This effectively decouples a high-capacity transformer generator from a much smaller inference model. It is different from most of the existing methods, e.g. MAML where the generator and the executing model share the same architecture.
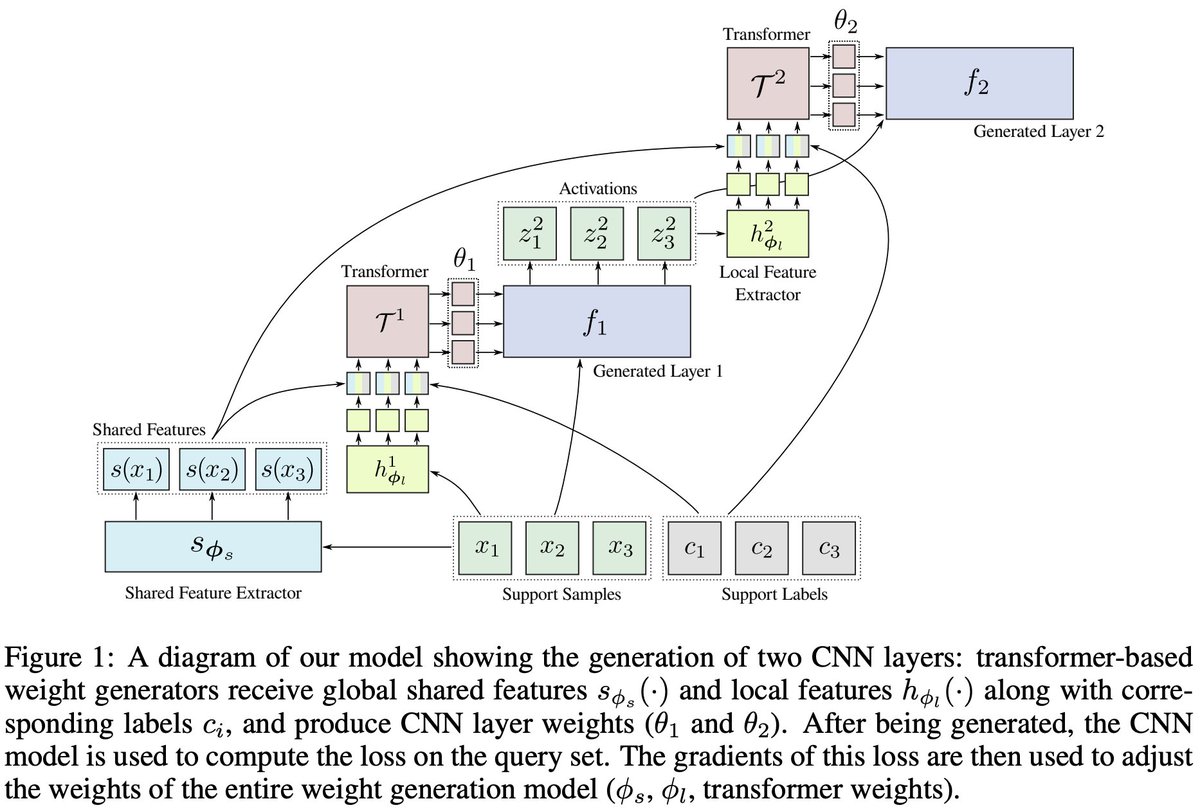
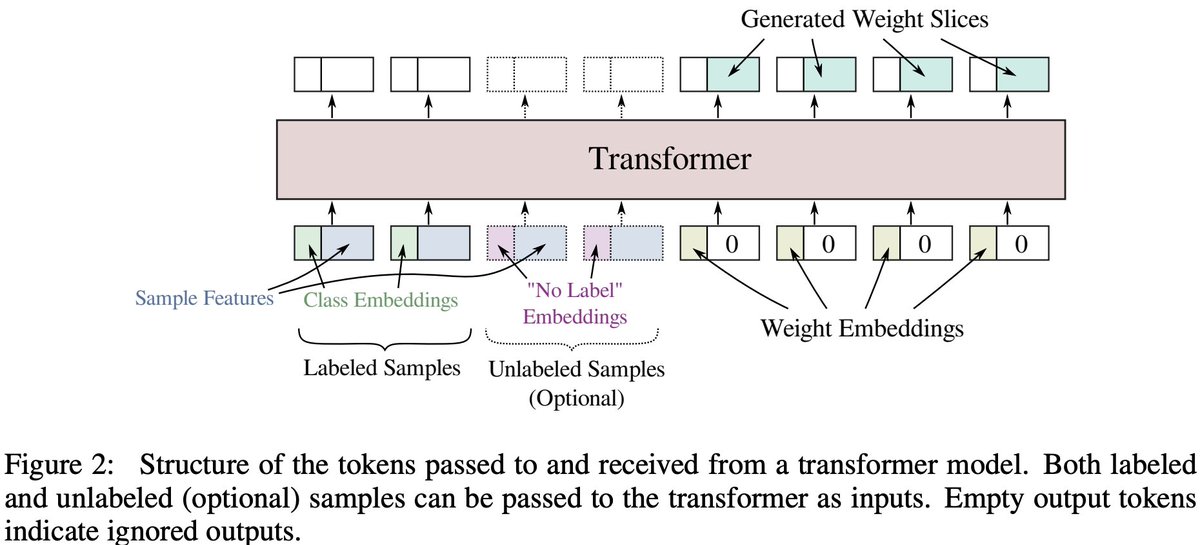
4) CNN weights are generated layer-by-layer from a combination of layer embedding (features from the last generated layer), and image w/ class embeddings (features directly from the data). The final weights are extracted from output of self-attention (similar to [CLS] tokens).
5) What is cool is that we can also add unlabeled samples from the support set into the mix, effectively allowing for semi-supervised few-shot learning!