
Suppose that for a given setup, price hits target before it reaches invalidation 70% of the time. Great, right? But getting filled is not guaranteed.
The more right you are about your trade setup, the less likely you are to get filled
By extension, getting filled actually lowers the Bayesian probability that you are right
Should I sacrifice some RRR to get filled more often?
The eternal dilemma of contrarian trading

Suppose that for a given setup, price hits target before it reaches invalidation 70% of the time. Great, right? But getting filled is not guaranteed.
Scenario 2: If only 40 out of 100 limits get filled, expected hit rate is 25%
Both scenarios have 30 losses in expectation, but the hit rate in the first is >2x better simply because more trades were taken
EV = hitrate * avg_win_R + (1-hitrate) * avg_loss_R
So we want argmax(EV), and we can compute this by seeing how hitrate and avg_win_R affect the EV of the setup.
Here's a real example where I completed this optimization.
- the average win R tends to increase ("W:PR")
- the number of losses ("L") stays constant at 31
- but the number of trades taken decreases ("#")
- so the hit rate decreases, from a max of 67.7% to a min of 11.4%.
- Understand the tradeoff between RRR and hit rate. I talked about limit orders in this thread but a similar relationship applies to market entries too
- There are no easy answers here. Only the prospect of hard work collecting good data and learning from it.
💪
@Captain_Kole1 @melodyofrhythm @ape_rture @realadamli @7ommyZero @voicelessFvoice
More from Trading

TradingView isn't just charts
It's much more powerful than you think
9 things TradingView can do, you'll wish you knew yesterday: 🧵
Collaborated with @niki_poojary
1/ Free Multi Timeframe Analysis
Step 1. Download Vivaldi Browser
Step 2. Login to trading view
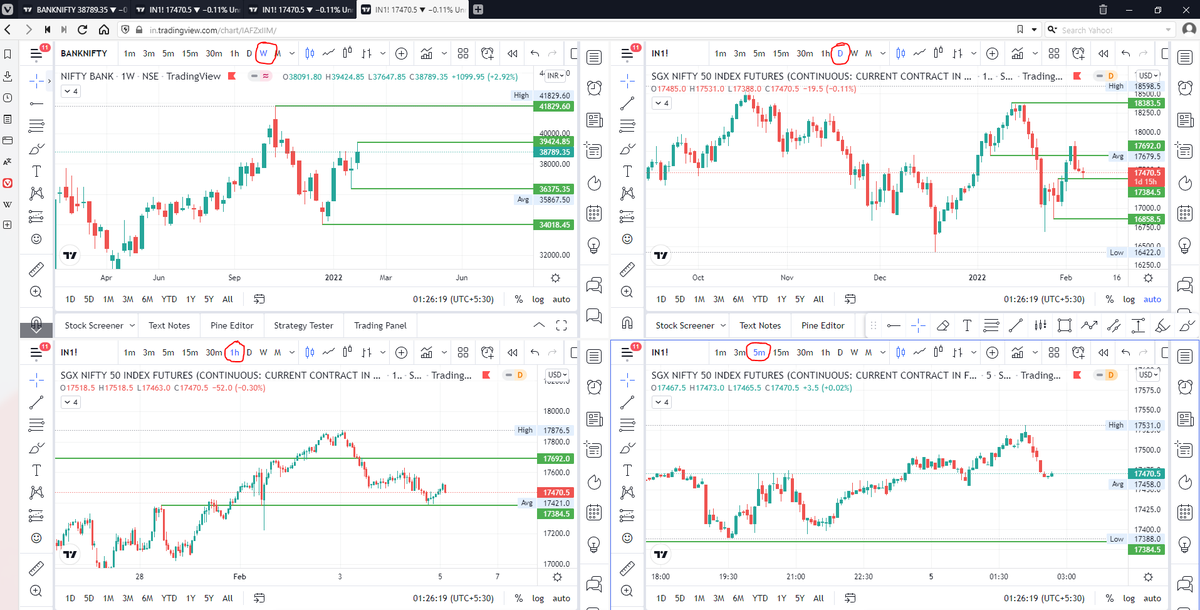
Step 3. Open bank nifty chart in 4 separate windows
Step 4. Click on the first tab and shift + click by mouse on the last tab.
Step 5. Select "Tile all 4 tabs"
What happens is you get 4 charts joint on one screen.
Refer to the attached picture.
The best part about this is this is absolutely free to do.
Also, do note:
I do not have the paid version of trading view.
2/ Free Multiple Watchlists
Go through this informative thread where @sarosijghosh teaches you how to create multiple free watchlists in the free
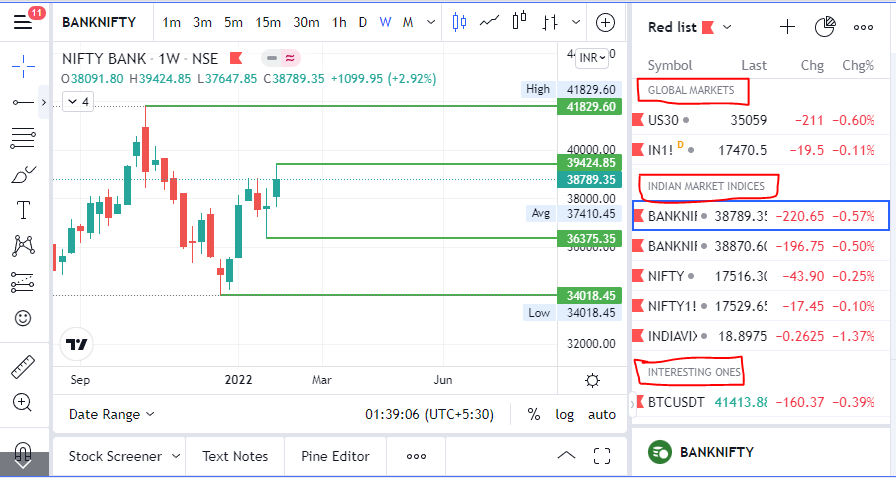
3/ Free Segregation into different headers/sectors
You can create multiple sections sector-wise for free.
1. Long tap on any index/stock and click on "Add section above."
2. Secgregate the stocks/indices based on where they belong.
Kinda like how I did in the picture below.
It's much more powerful than you think
9 things TradingView can do, you'll wish you knew yesterday: 🧵
Collaborated with @niki_poojary
1/ Free Multi Timeframe Analysis
Step 1. Download Vivaldi Browser
Step 2. Login to trading view
Step 3. Open bank nifty chart in 4 separate windows
Step 4. Click on the first tab and shift + click by mouse on the last tab.
Step 5. Select "Tile all 4 tabs"
What happens is you get 4 charts joint on one screen.
Refer to the attached picture.
The best part about this is this is absolutely free to do.
Also, do note:
I do not have the paid version of trading view.
2/ Free Multiple Watchlists
Go through this informative thread where @sarosijghosh teaches you how to create multiple free watchlists in the free
\U0001d5e0\U0001d602\U0001d5f9\U0001d601\U0001d5f6\U0001d5fd\U0001d5f9\U0001d5f2 \U0001d600\U0001d5f2\U0001d5f0\U0001d601\U0001d5fc\U0001d5ff \U0001d604\U0001d5ee\U0001d601\U0001d5f0\U0001d5f5\U0001d5f9\U0001d5f6\U0001d600\U0001d601 \U0001d5fc\U0001d5fb \U0001d5e7\U0001d5ff\U0001d5ee\U0001d5f1\U0001d5f6\U0001d5fb\U0001d5f4\U0001d603\U0001d5f6\U0001d5f2\U0001d604 \U0001d602\U0001d600\U0001d5f6\U0001d5fb\U0001d5f4 \U0001d601\U0001d5f5\U0001d5f2 \U0001d5d9\U0001d5e5\U0001d5d8\U0001d5d8 \U0001d603\U0001d5f2\U0001d5ff\U0001d600\U0001d5f6\U0001d5fc\U0001d5fb!
— Sarosij Ghosh (@sarosijghosh) September 18, 2021
A THREAD \U0001f9f5
Please Like and Re-Tweet. It took a lot of effort to put this together. #StockMarket #TradingView #trading #watchlist #Nifty500 #stockstowatch
3/ Free Segregation into different headers/sectors
You can create multiple sections sector-wise for free.
1. Long tap on any index/stock and click on "Add section above."
2. Secgregate the stocks/indices based on where they belong.
Kinda like how I did in the picture below.






You May Also Like



This is a pretty valiant attempt to defend the "Feminist Glaciology" article, which says conventional wisdom is wrong, and this is a solid piece of scholarship. I'll beg to differ, because I think Jeffery, here, is confusing scholarship with "saying things that seem right".
The article is, at heart, deeply weird, even essentialist. Here, for example, is the claim that proposing climate engineering is a "man" thing. Also a "man" thing: attempting to get distance from a topic, approaching it in a disinterested fashion.

Also a "man" thing—physical courage. (I guess, not quite: physical courage "co-constitutes" masculinist glaciology along with nationalism and colonialism.)

There's criticism of a New York Times article that talks about glaciology adventures, which makes a similar point.

At the heart of this chunk is the claim that glaciology excludes women because of a narrative of scientific objectivity and physical adventure. This is a strong claim! It's not enough to say, hey, sure, sounds good. Is it true?
Imagine for a moment the most obscurantist, jargon-filled, po-mo article the politically correct academy might produce. Pure SJW nonsense. Got it? Chances are you're imagining something like the infamous "Feminist Glaciology" article from a few years back.https://t.co/NRaWNREBvR pic.twitter.com/qtSFBYY80S
— Jeffrey Sachs (@JeffreyASachs) October 13, 2018
The article is, at heart, deeply weird, even essentialist. Here, for example, is the claim that proposing climate engineering is a "man" thing. Also a "man" thing: attempting to get distance from a topic, approaching it in a disinterested fashion.
Also a "man" thing—physical courage. (I guess, not quite: physical courage "co-constitutes" masculinist glaciology along with nationalism and colonialism.)
There's criticism of a New York Times article that talks about glaciology adventures, which makes a similar point.
At the heart of this chunk is the claim that glaciology excludes women because of a narrative of scientific objectivity and physical adventure. This is a strong claim! It's not enough to say, hey, sure, sounds good. Is it true?



Recently, the @CNIL issued a decision regarding the GDPR compliance of an unknown French adtech company named "Vectaury". It may seem like small fry, but the decision has potential wide-ranging impacts for Google, the IAB framework, and today's adtech. It's thread time! 👇
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
It's all in French, but if you're up for it you can read:
• Their blog post (lacks the most interesting details): https://t.co/PHkDcOT1hy
• Their high-level legal decision: https://t.co/hwpiEvjodt
• The full notification: https://t.co/QQB7rfynha
I've read it so you needn't!
Vectaury was collecting geolocation data in order to create profiles (eg. people who often go to this or that type of shop) so as to power ad targeting. They operate through embedded SDKs and ad bidding, making them invisible to users.
The @CNIL notes that profiling based off of geolocation presents particular risks since it reveals people's movements and habits. As risky, the processing requires consent — this will be the heart of their assessment.
Interesting point: they justify the decision in part because of how many people COULD be targeted in this way (rather than how many have — though they note that too). Because it's on a phone, and many have phones, it is considered large-scale processing no matter what.
