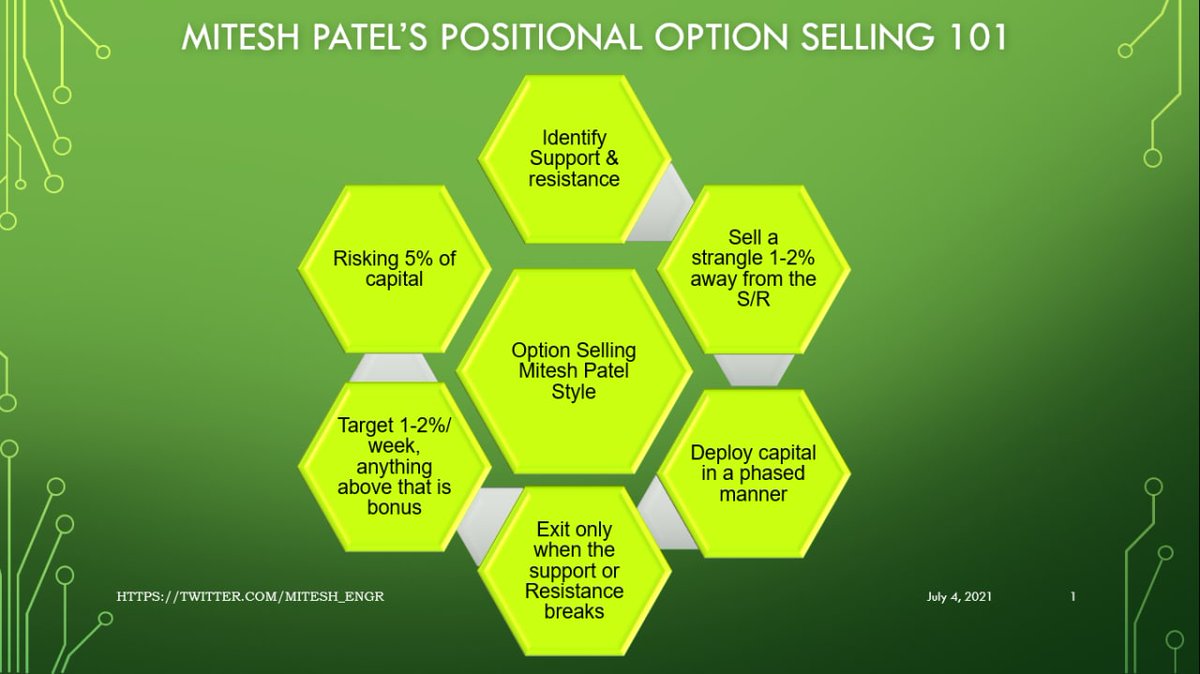
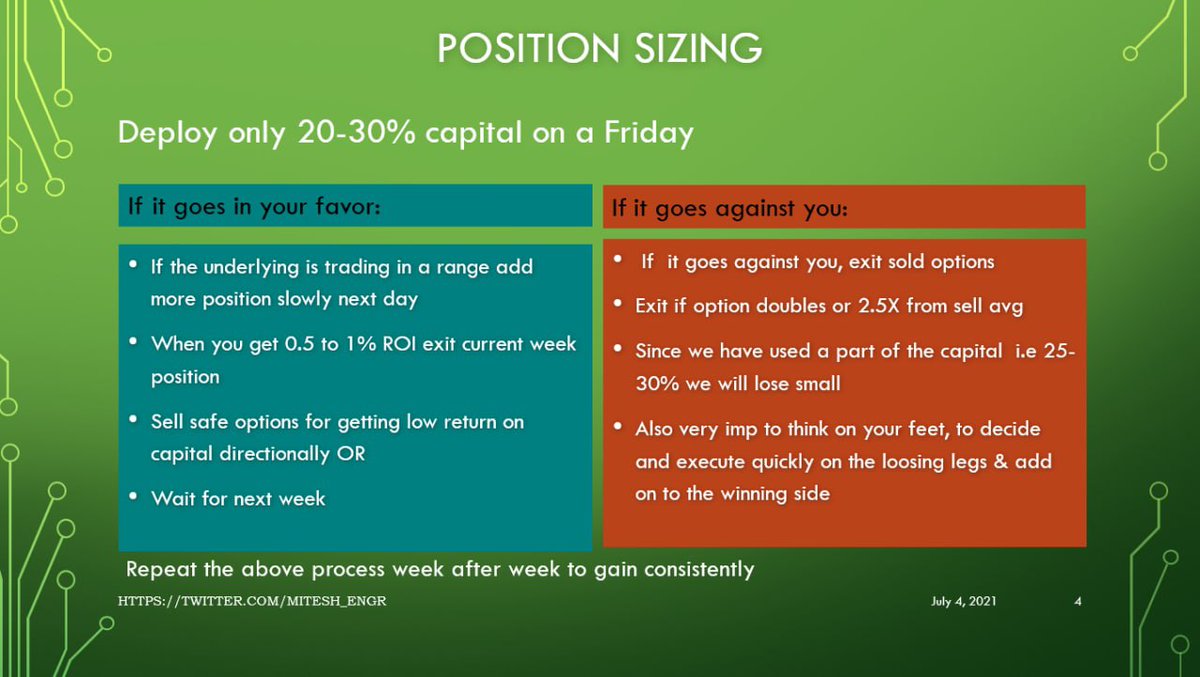
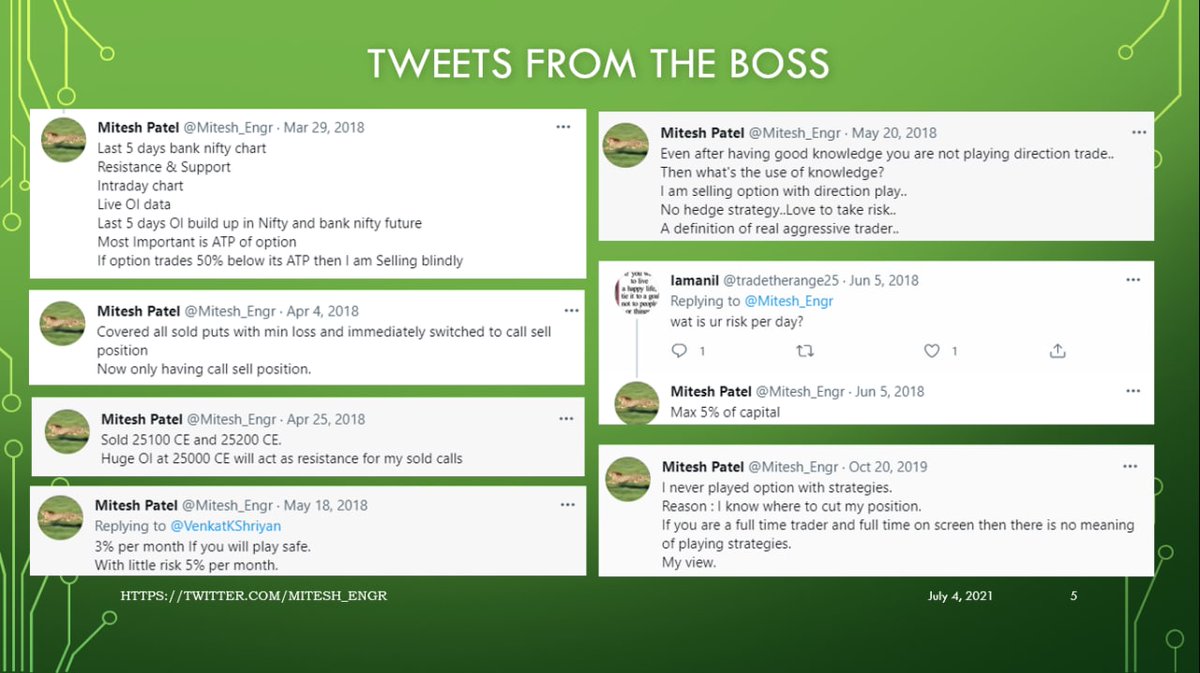
If you're interested in DB internals, stop what you're doing and watch @CMUDB Quarantine Talk from Nico+Cesar about @SQLServer's Cascades query optimizer: https://t.co/FCdsbHHEaD
Many talks this semester were good. This one is the best. My thread provides key takeaways
Answer: @cosmosdb is using it. @SQLServer is more conservative and using a minor form of it.
More from Internet







🚨 🦮 Seven ways to test for accessibility using only what is already in browser developer tools of Chromium browsers https://t.co/C7kdbigHGE
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
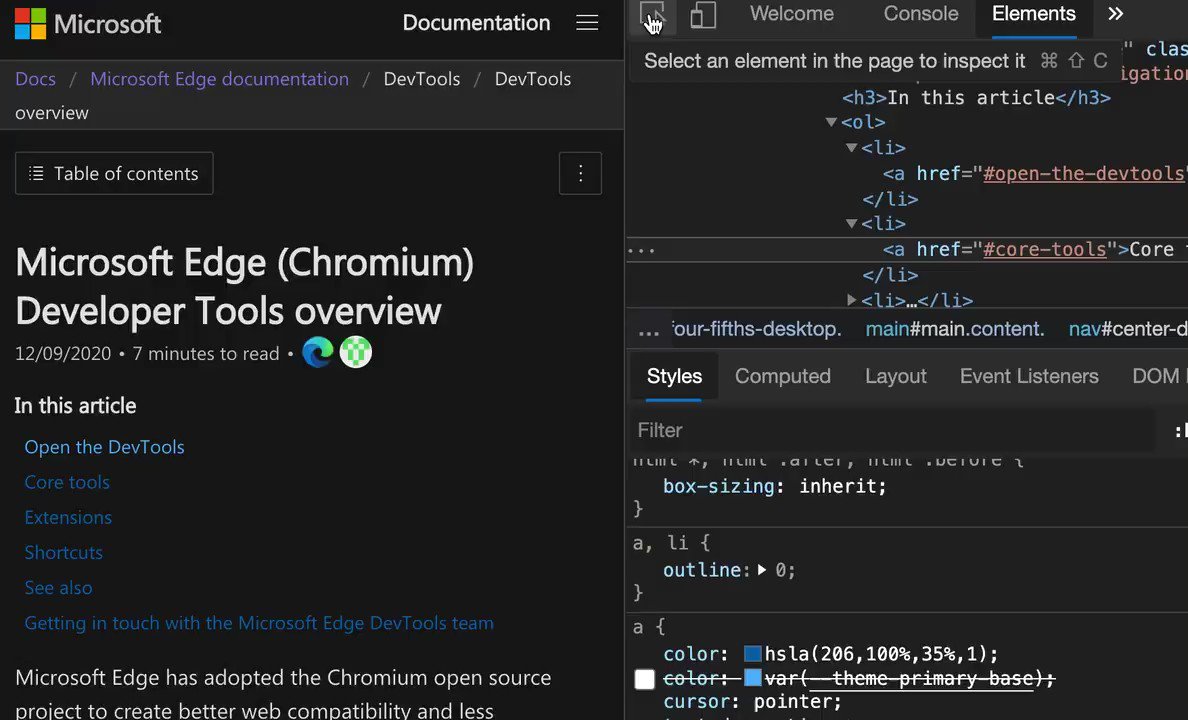
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
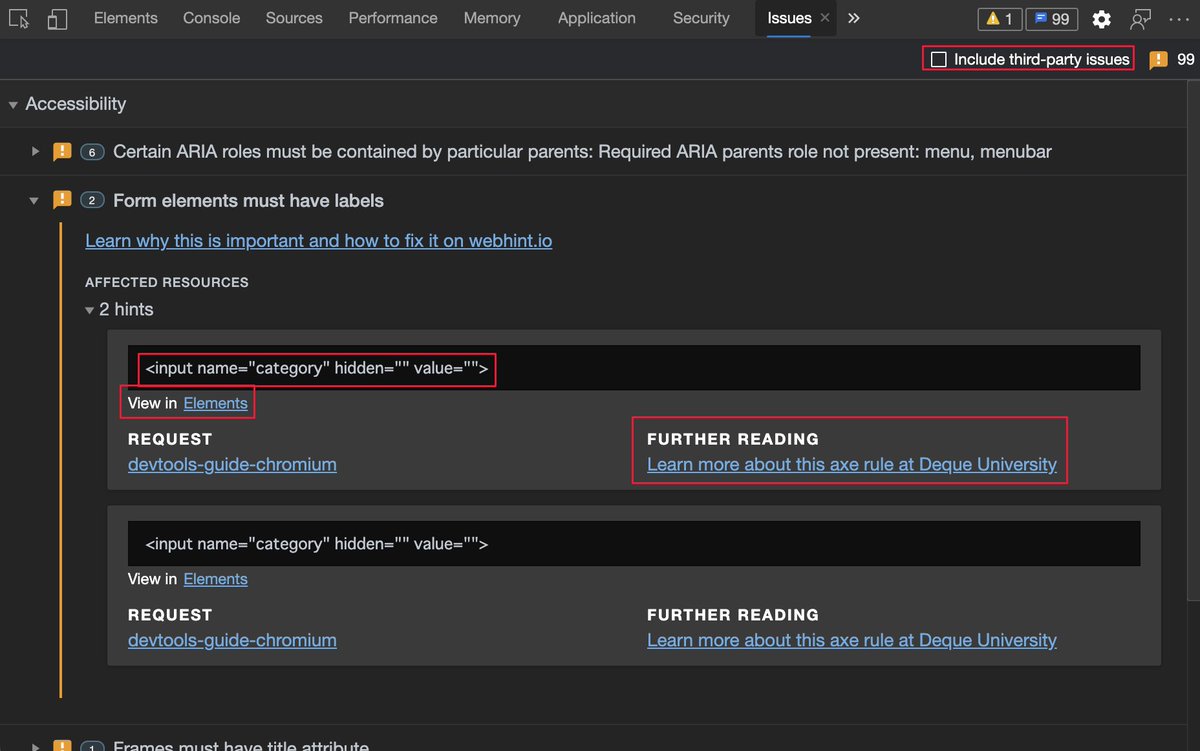
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
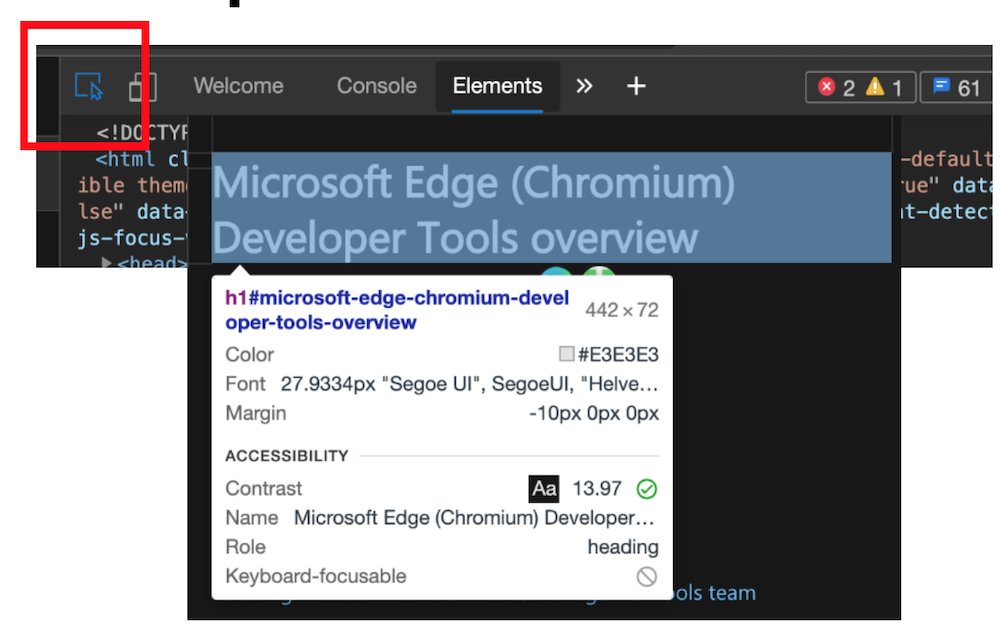
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.

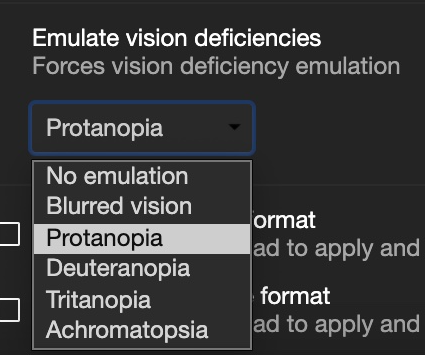
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb
@MSEdgeDev @EdgeDevTools @ChromiumDev
#tools #accessibility #browsers
Also, a thread: 👇🏼
Issues pane, powered by @webhintio, listing accessibility issues with explanations why these are problems, links to more info and direct links to the tools where to fix the problem. https://t.co/4K5RynHhbg
The inspect element overlay showing accessibility relevant information of the element, including contrast information, ARIA name, role and if it can be focused via keyboard.
Colour picker with contrast information offering colours that are AA/AAA compliant. You can also see compliant colours indicated by a line on the colour patch.
Note: the current algorithm fails to take font weight into consideration, that's why there will be a new one.
Vision deficit ("colour blindness") emulation. You can see what your product looks like for different visitors.
https://t.co/bxj1vySCAb


We’ve spent the last ten months building #CitizenBrowser, a project that aims to peek inside the Black Box of social media algorithms, by building a nationwide panel to share data with us. Today, we are publishing our first story from the project. /1
.@corintxt crunched the numbers and found that after Facebook flipped the switch for political ads, partisan content elbowed out reputable news outlets in our panelists’ news feeds. https://t.co/Z0kibSBeQZ /2
You can learn more in our methodology, where we describe how we did this and what steps we took to ensure that we preserved the panelists' privacy. https://t.co/UYbTXAjy5i /3
Personally, this project is the culmination of years of experiments trying to figure out how to collect data from social media platforms in a way that can lead to meaningful reporting. I’ve described a couple of highlights below 👇 /4
My first attempt was in 2016 at Propublica, when I was working with @JuliaAngwin . We were interested in seeing if there was a difference in the Ad interests FB disclosed to users in their settings and the interests they showed to marketers. /5
.@corintxt crunched the numbers and found that after Facebook flipped the switch for political ads, partisan content elbowed out reputable news outlets in our panelists’ news feeds. https://t.co/Z0kibSBeQZ /2
You can learn more in our methodology, where we describe how we did this and what steps we took to ensure that we preserved the panelists' privacy. https://t.co/UYbTXAjy5i /3
Personally, this project is the culmination of years of experiments trying to figure out how to collect data from social media platforms in a way that can lead to meaningful reporting. I’ve described a couple of highlights below 👇 /4
My first attempt was in 2016 at Propublica, when I was working with @JuliaAngwin . We were interested in seeing if there was a difference in the Ad interests FB disclosed to users in their settings and the interests they showed to marketers. /5




You May Also Like

“We don’t negotiate salaries” is a negotiation tactic.
Always. No, your company is not an exception.
A tactic I don’t appreciate at all because of how unfairly it penalizes low-leverage, junior employees, and those loyal enough not to question it, but that’s negotiation for you after all. Weaponized information asymmetry.
Listen to Aditya
And by the way, you should never be worried that an offer would be withdrawn if you politely negotiate.
I have seen this happen *extremely* rarely, mostly to women, and anyway is a giant red flag. It suggests you probably didn’t want to work there.
You wish there was no negotiating so it would all be more fair? I feel you, but it’s not happening.
Instead, negotiate hard, use your privilege, and then go and share numbers with your underrepresented and underpaid colleagues. […]
Always. No, your company is not an exception.
A tactic I don’t appreciate at all because of how unfairly it penalizes low-leverage, junior employees, and those loyal enough not to question it, but that’s negotiation for you after all. Weaponized information asymmetry.
Listen to Aditya
"we don't negotiate salaries" really means "we'd prefer to negotiate massive signing bonuses and equity grants, but we'll negotiate salary if you REALLY insist" https://t.co/80k7nWAMoK
— Aditya Mukerjee, the Otterrific \U0001f3f3\ufe0f\u200d\U0001f308 (@chimeracoder) December 4, 2018
And by the way, you should never be worried that an offer would be withdrawn if you politely negotiate.
I have seen this happen *extremely* rarely, mostly to women, and anyway is a giant red flag. It suggests you probably didn’t want to work there.
You wish there was no negotiating so it would all be more fair? I feel you, but it’s not happening.
Instead, negotiate hard, use your privilege, and then go and share numbers with your underrepresented and underpaid colleagues. […]