
If you're interested in DB internals, stop what you're doing and watch @CMUDB Quarantine Talk from Nico+Cesar about @SQLServer's Cascades query optimizer: https://t.co/FCdsbHHEaD
Many talks this semester were good. This one is the best. My thread provides key takeaways
Answer: @cosmosdb is using it. @SQLServer is more conservative and using a minor form of it.
More from Internet

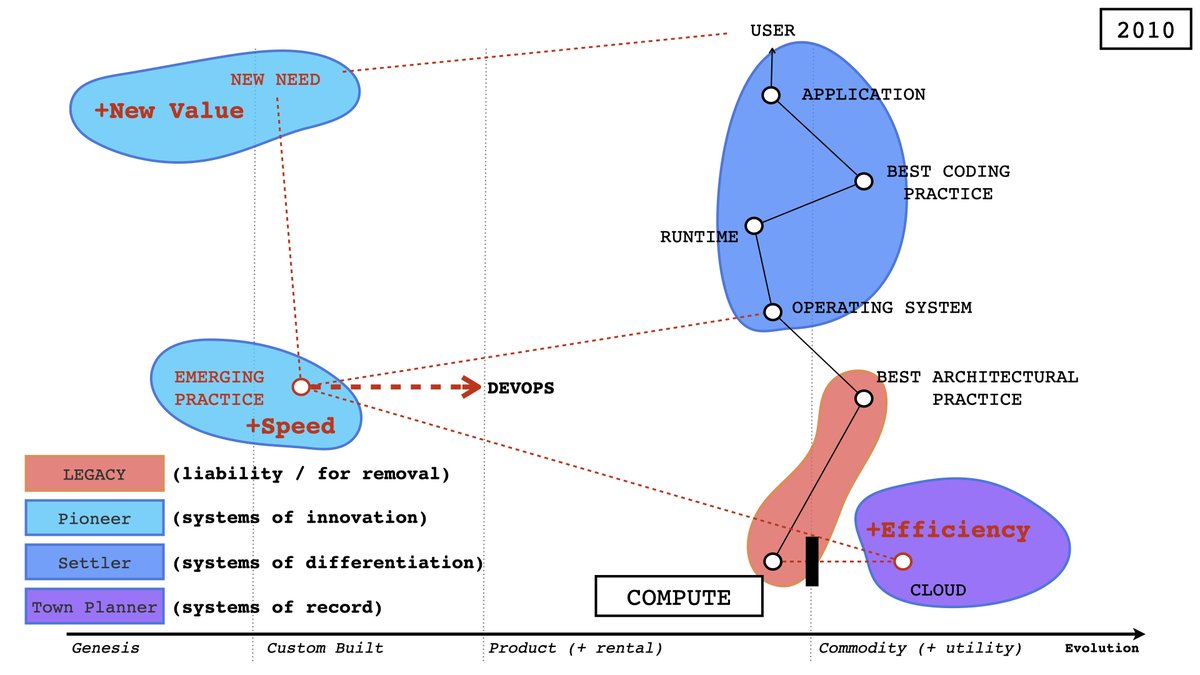
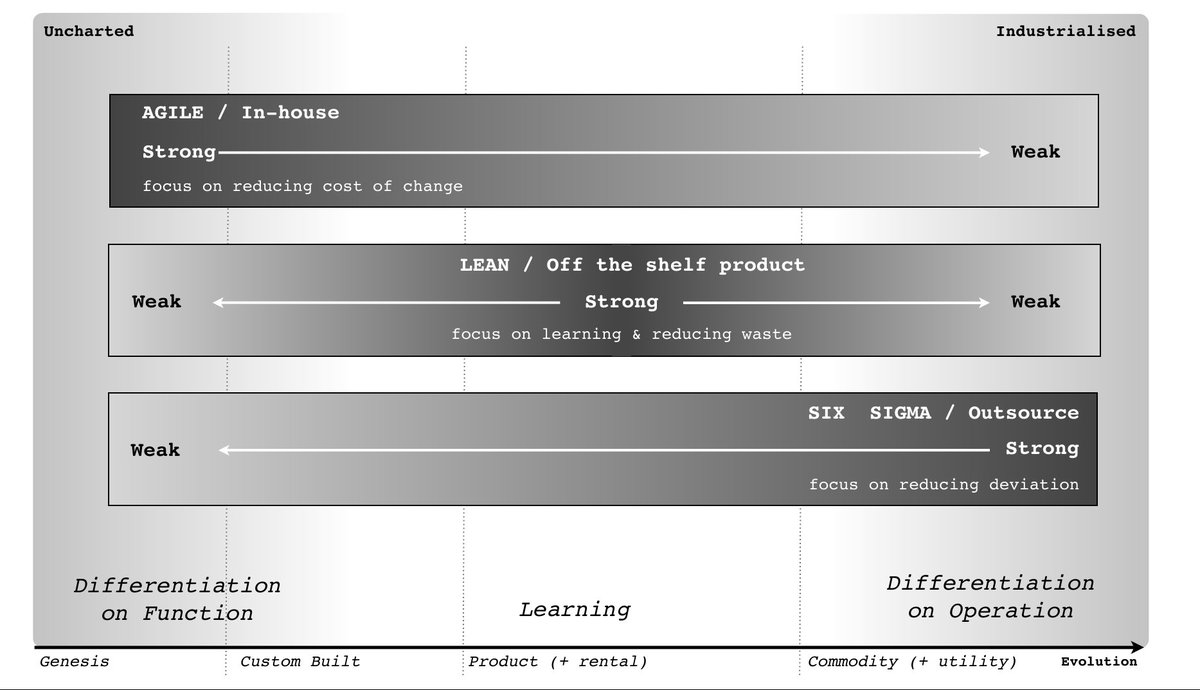




There are lots of problems with ad-tech:
* being spied on all the time means that the people of the 21st century are less able to be their authentic selves;
* any data that is collected and retained will eventually breach, creating untold harms;
1/

* data-collection enables for discriminatory business practices ("digital redlining");
* the huge, tangled hairball of adtech companies siphons lots (maybe even most) of the money that should go creators and media orgs; and
2/
* anti-adblock demands browsers and devices that thwart their owners' wishes, a capability that can be exploited for even more nefarious purposes;
That's all terrible, but it's also IRONIC, since it appears that, in addition to everything else, ad-tech is a fraud, a bezzle.
3/
Bezzle was John Kenneth Galbraith's term for "the magic interval when a confidence trickster knows he has the money he has appropriated but the victim does not yet understand that he has lost it." That is, a rotten log that has yet to be turned over.
4/
Bezzles unwind slowly, then all at once. We've had some important peeks under ad-tech's rotten log, and they're increasing in both intensity and velocity. If you follow @Chronotope, you've had a front-row seat to the
* being spied on all the time means that the people of the 21st century are less able to be their authentic selves;
* any data that is collected and retained will eventually breach, creating untold harms;
1/
* data-collection enables for discriminatory business practices ("digital redlining");
* the huge, tangled hairball of adtech companies siphons lots (maybe even most) of the money that should go creators and media orgs; and
2/
* anti-adblock demands browsers and devices that thwart their owners' wishes, a capability that can be exploited for even more nefarious purposes;
That's all terrible, but it's also IRONIC, since it appears that, in addition to everything else, ad-tech is a fraud, a bezzle.
3/
Bezzle was John Kenneth Galbraith's term for "the magic interval when a confidence trickster knows he has the money he has appropriated but the victim does not yet understand that he has lost it." That is, a rotten log that has yet to be turned over.
4/
Bezzles unwind slowly, then all at once. We've had some important peeks under ad-tech's rotten log, and they're increasing in both intensity and velocity. If you follow @Chronotope, you've had a front-row seat to the
The numbers are all fking fake, the metrics are bullshit, the agencies responsible for enforcing good practices are knowing bullshiters enforcing and profiting off all the fake numbers and none of the models make sense at scale of actual human users. https://t.co/sfmdrxGBNJ pic.twitter.com/thvicDEL29
— Aram Zucker-Scharff (@Chronotope) December 26, 2018


You May Also Like










So the cryptocurrency industry has basically two products, one which is relatively benign and doesn't have product market fit, and one which is malignant and does. The industry has a weird superposition of understanding this fact and (strategically?) not understanding it.
The benign product is sovereign programmable money, which is historically a niche interest of folks with a relatively clustered set of beliefs about the state, the literary merit of Snow Crash, and the utility of gold to the modern economy.
This product has narrow appeal and, accordingly, is worth about as much as everything else on a 486 sitting in someone's basement is worth.
The other product is investment scams, which have approximately the best product market fit of anything produced by humans. In no age, in no country, in no city, at no level of sophistication do people consistently say "Actually I would prefer not to get money for nothing."
This product needs the exchanges like they need oxygen, because the value of it is directly tied to having payment rails to move real currency into the ecosystem and some jurisdictional and regulatory legerdemain to stay one step ahead of the banhammer.
If everyone was holding bitcoin on the old x86 in their parents basement, we would be finding a price bottom. The problem is the risk is all pooled at a few brokerages and a network of rotten exchanges with counter party risk that makes AIG circa 2008 look like a good credit.
— Greg Wester (@gwestr) November 25, 2018
The benign product is sovereign programmable money, which is historically a niche interest of folks with a relatively clustered set of beliefs about the state, the literary merit of Snow Crash, and the utility of gold to the modern economy.
This product has narrow appeal and, accordingly, is worth about as much as everything else on a 486 sitting in someone's basement is worth.
The other product is investment scams, which have approximately the best product market fit of anything produced by humans. In no age, in no country, in no city, at no level of sophistication do people consistently say "Actually I would prefer not to get money for nothing."
This product needs the exchanges like they need oxygen, because the value of it is directly tied to having payment rails to move real currency into the ecosystem and some jurisdictional and regulatory legerdemain to stay one step ahead of the banhammer.