

Today is a good day to start a thread about Mount Airy Casino Resort. It may take a while to cover all the territory.
Let’s start with some ancient history.

D’Elia was the head of the Bufalino crime family.
“DeNaples relinquished control of the casino in 2009 to avoid prosecution on charges he lied to the Pennsylvania Gaming Control Board about his affiliations with organized crime figures when he applied for his gaming license.
https://t.co/OpaA1KfxVQ
The Office of Enforcement Counsel disagreed.
https://t.co/tHonLyI6HF
https://t.co/1CScG1fpoN

https://t.co/444Oi0Kz27
Boohoo.
https://t.co/OpaA1KfxVQ

[I was today years old when I learned there is a Mafia Wiki.]
https://t.co/NedP5Mpdik

“In 1978, DeNaples pleaded no contest to a conspiracy charge of defrauding the government of more than $500,000 in contracts relating to the cleanup and recovery of the City of Scranton in the aftermath of Hurricane Agnes.”

But we still have a few gaps to fill before we arrive at the present day.

La Cosa Nostra founder Bufalino allegedly ordered the hit on Hoffa “because of concerns the one-time union kingpin might spill details of his involvement in the Castro plot.”
💥
https://t.co/c2z5V9aUdW

“DeNaples, Birkbeck alleges, was initially granted a casino license to operate a slots parlor in the Poconos after corralling business associates to donate $600,000 to Rendell's campaign coffers.”
Is bribe too harsh? Shall we use bundle?
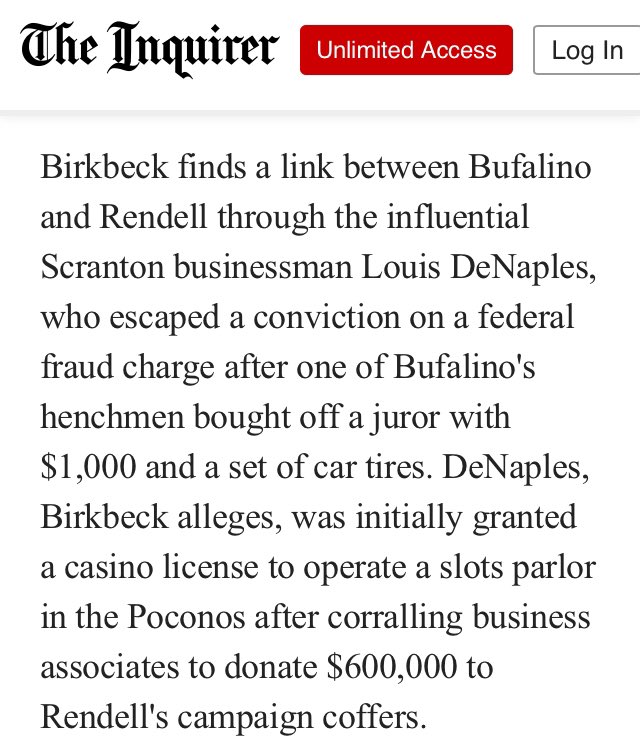
This article 😅
https://t.co/B0bA47yT1p
😟
https://t.co/9v79LlMHFP

🚨 He owns his own bank (probably more.) 🚨

https://t.co/gs9wwQShdn
Corbett lost his 2014 re-election bid.
https://t.co/x1f8BItgsA
Louis DeNaples, who founded Mount Airy Casino Resort, got forced to pass the biz to his kids, & then started throwing around big bucks to politicians of all stripes. & why shouldn’t he?
He’s the chairman of the board at $FNCB.
https://t.co/irvnqCrkDl
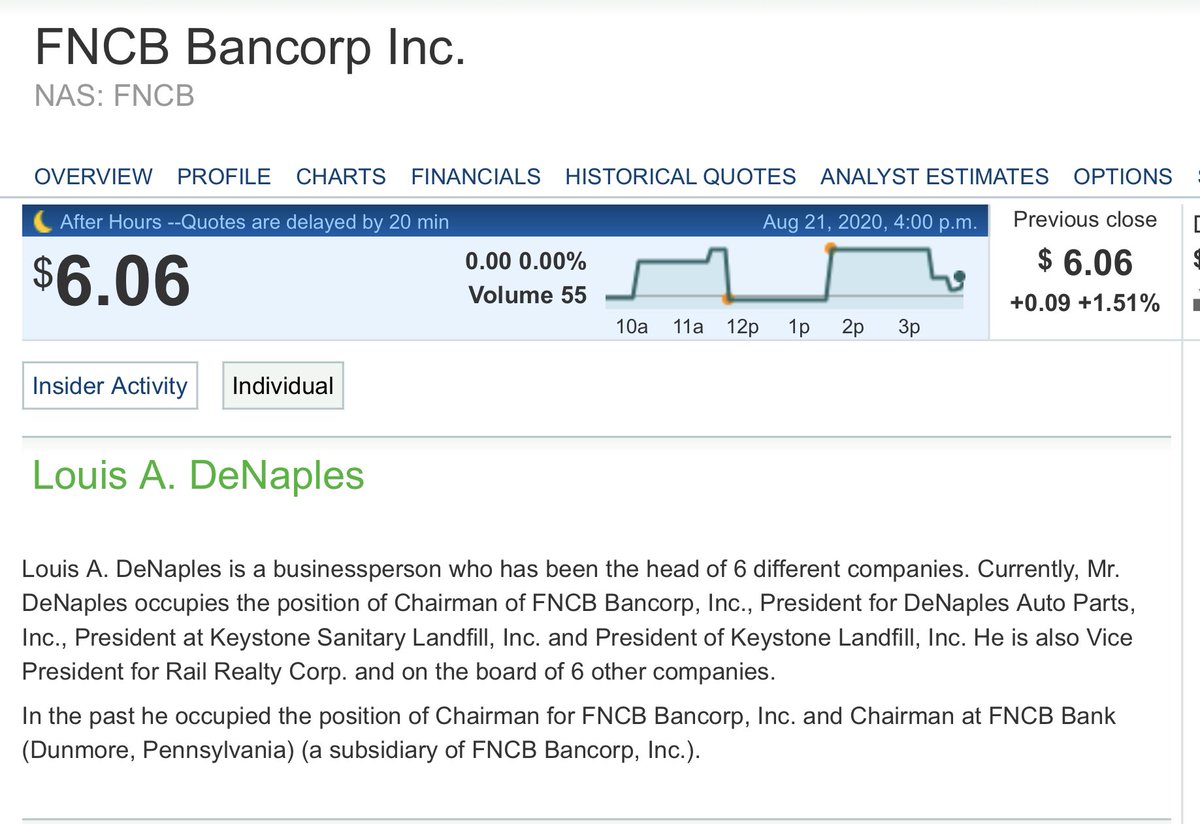
You can see the bank changed its name in 2016, but let’s not delve into that just now.

https://t.co/4CBUGUyCiU
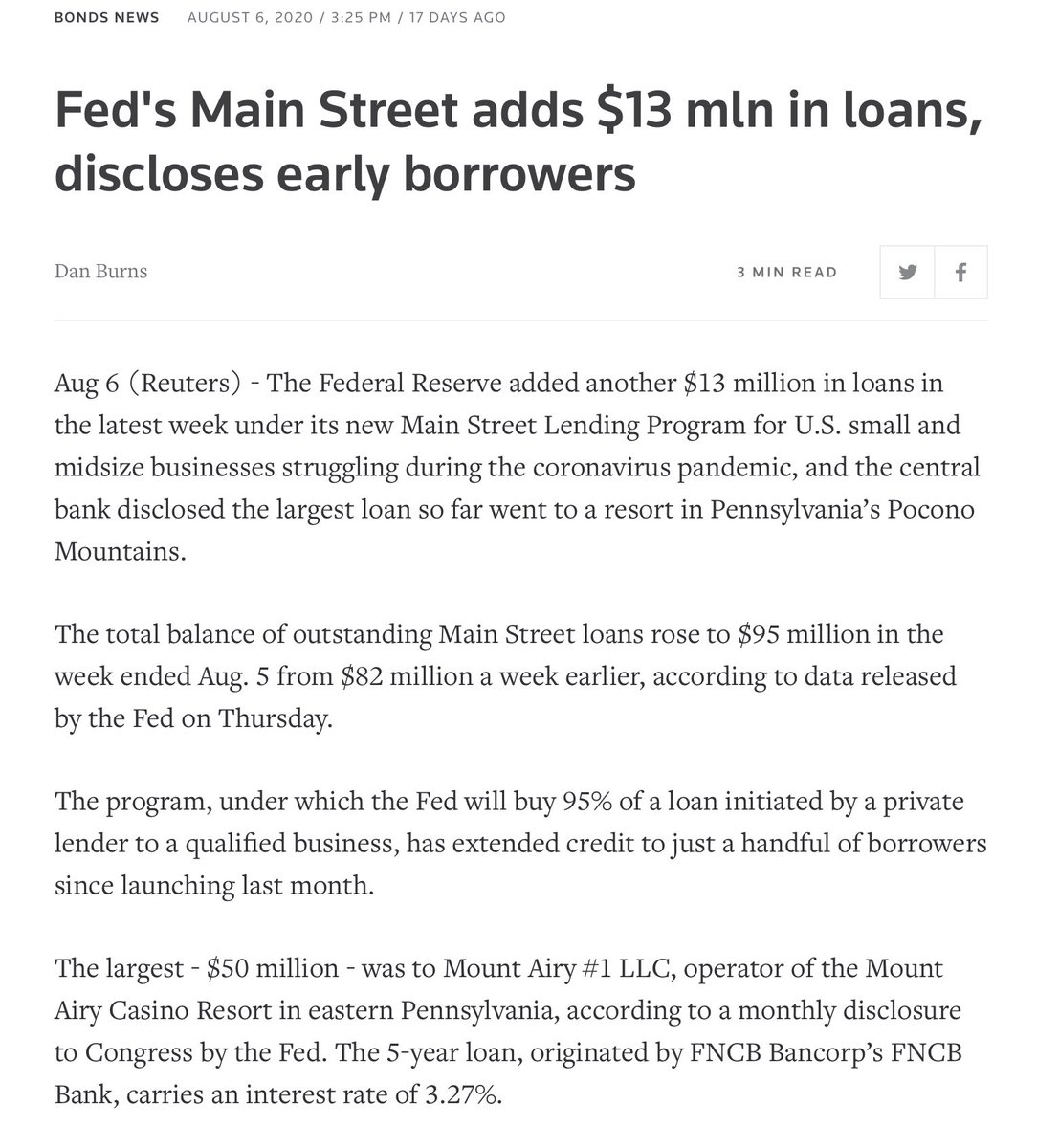

More from All









How can we use language supervision to learn better visual representations for robotics?
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)

Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
Introducing Voltron: Language-Driven Representation Learning for Robotics!
Paper: https://t.co/gIsRPtSjKz
Models: https://t.co/NOB3cpATYG
Evaluation: https://t.co/aOzQu95J8z
🧵👇(1 / 12)
Videos of humans performing everyday tasks (Something-Something-v2, Ego4D) offer a rich and diverse resource for learning representations for robotic manipulation.
Yet, an underused part of these datasets are the rich, natural language annotations accompanying each video. (2/12)
The Voltron framework offers a simple way to use language supervision to shape representation learning, building off of prior work in representations for robotics like MVP (https://t.co/Pb0mk9hb4i) and R3M (https://t.co/o2Fkc3fP0e).
The secret is *balance* (3/12)
Starting with a masked autoencoder over frames from these video clips, make a choice:
1) Condition on language and improve our ability to reconstruct the scene.
2) Generate language given the visual representation and improve our ability to describe what's happening. (4/12)
By trading off *conditioning* and *generation* we show that we can learn 1) better representations than prior methods, and 2) explicitly shape the balance of low and high-level features captured.
Why is the ability to shape this balance important? (5/12)
You May Also Like



Joe Rogan's podcast is now is listened to 1.5+ billion times per year at around $50-100M/year revenue.
Independent and 100% owned by Joe, no networks, no middle men and a 100M+ people audience.
👏
https://t.co/RywAiBxA3s
Joe is the #1 / #2 podcast (depends per week) of all podcasts
120 million plays per month source https://t.co/k7L1LfDdcM
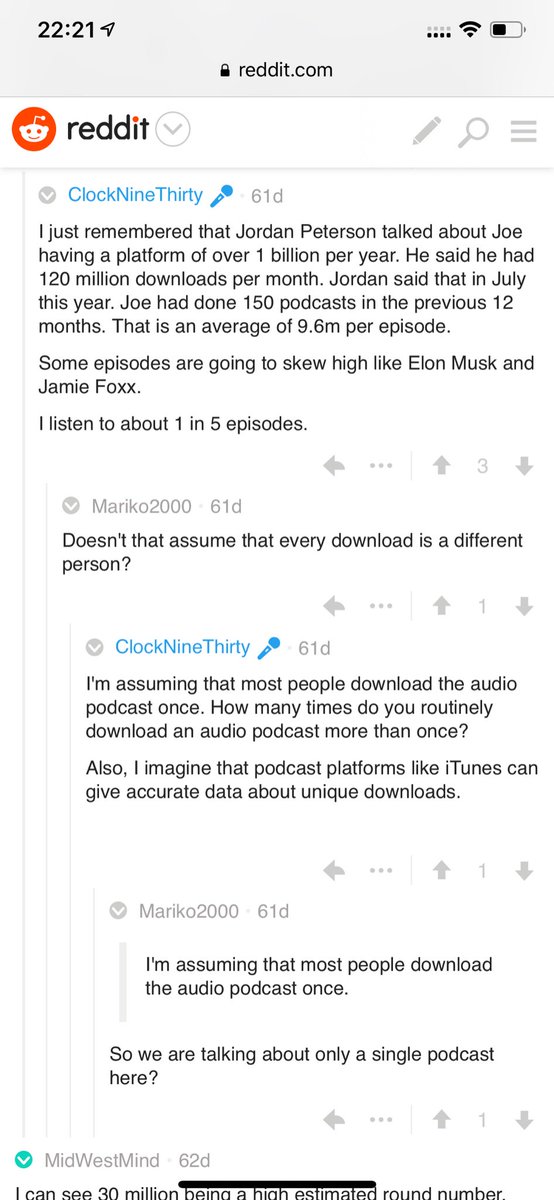
https://t.co/aGcYnVDpMu
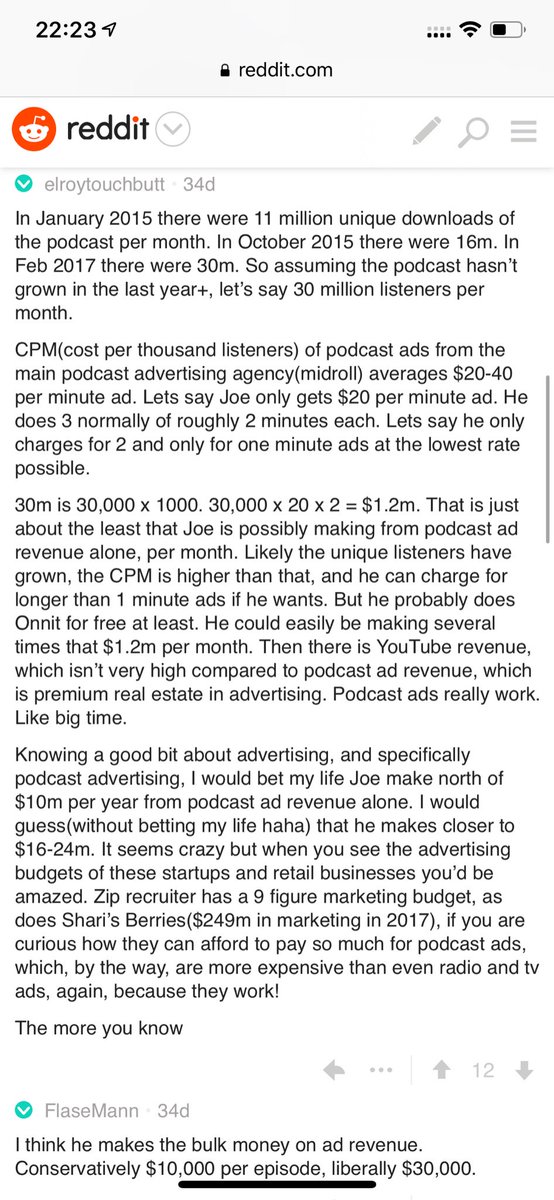
Independent and 100% owned by Joe, no networks, no middle men and a 100M+ people audience.
👏
https://t.co/RywAiBxA3s
Joe is the #1 / #2 podcast (depends per week) of all podcasts
120 million plays per month source https://t.co/k7L1LfDdcM
https://t.co/aGcYnVDpMu







