
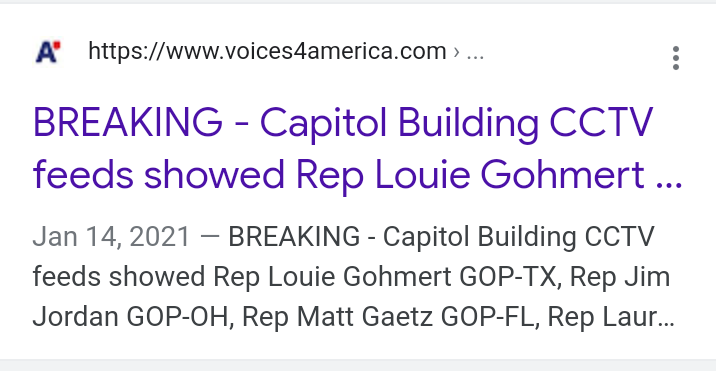
@colonvalbert I know of only one source (apart from Twitter folk) to have made this assertion about tours and some of these MOC. Do you have any authoritative corroboration?
More from All

Took me 5 years to get the best Chartink scanners for Stock Market, but you’ll get it in 5 mminutes here ⏰
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times
Do Share the above tweet 👆
These are going to be very simple yet effective pure price action based scanners, no fancy indicators nothing - hope you liked it.
https://t.co/JU0MJIbpRV
52 Week High
One of the classic scanners very you will get strong stocks to Bet on.
https://t.co/V69th0jwBr
Hourly Breakout
This scanner will give you short term bet breakouts like hourly or 2Hr breakout
Volume shocker
Volume spurt in a stock with massive X times




You May Also Like





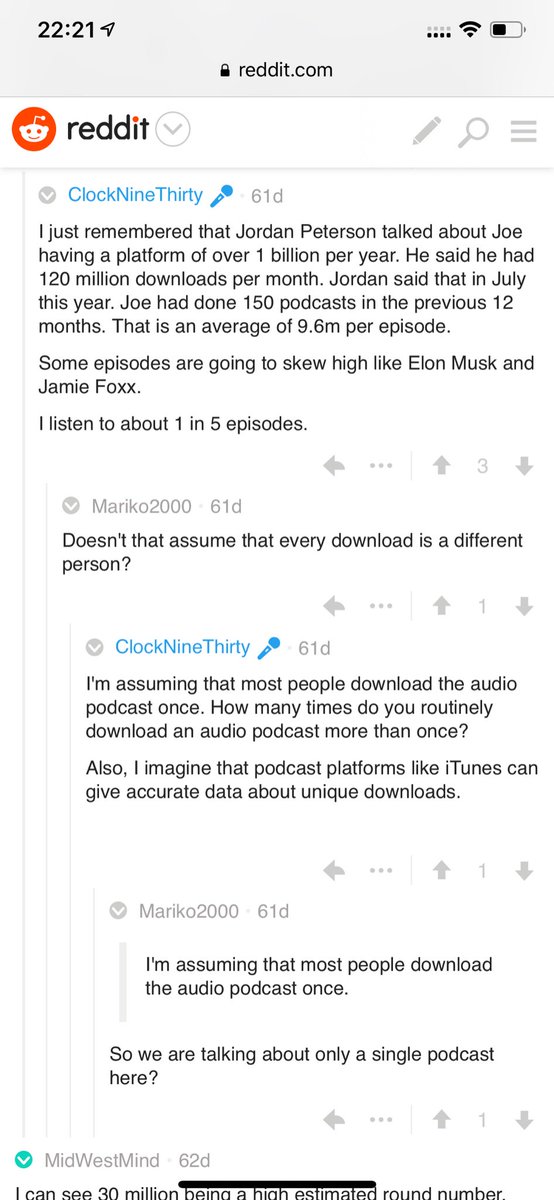
Joe Rogan's podcast is now is listened to 1.5+ billion times per year at around $50-100M/year revenue.
Independent and 100% owned by Joe, no networks, no middle men and a 100M+ people audience.
👏
https://t.co/RywAiBxA3s
Joe is the #1 / #2 podcast (depends per week) of all podcasts
120 million plays per month source https://t.co/k7L1LfDdcM
https://t.co/aGcYnVDpMu
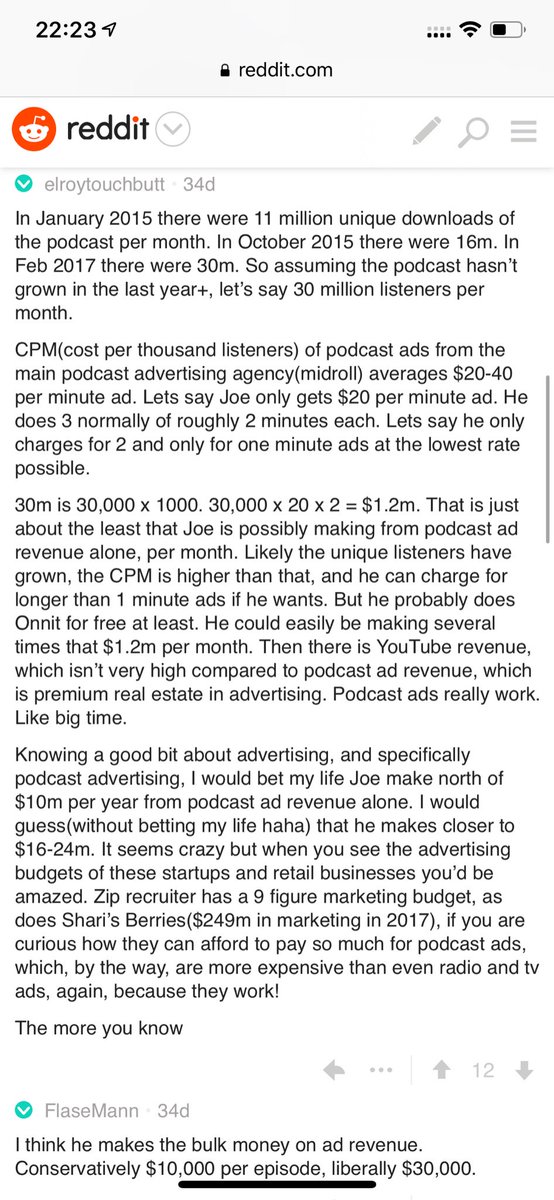
Independent and 100% owned by Joe, no networks, no middle men and a 100M+ people audience.
👏
https://t.co/RywAiBxA3s
Joe is the #1 / #2 podcast (depends per week) of all podcasts
120 million plays per month source https://t.co/k7L1LfDdcM
https://t.co/aGcYnVDpMu



